The AI video generation landscape shifted permanently on February 4, 2026, when Kuaishou released Kling 3.0. This wasn't another incremental update with modest improvements—it was a fundamental reimagining of what AI-generated video could achieve. For the first time, creators gained access to native 4K resolution at 60 frames per second, multi-shot narrative sequencing with character consistency, and synchronized audio generation within a single unified platform.
We've analyzed every benchmark, tested the workflows, and compared the specifications across all major models. This guide delivers the definitive technical breakdown of Kling 3.0, walking you through exactly what makes this release different from everything that came before it, and more importantly, how to leverage its capabilities for your own video production workflows.
What Makes Kling 3.0 Different From Previous Generations
The transition from Kling 2.6 to Kling 3.0 represents more than a version number bump. Previous iterations topped out at 1080p resolution with 30fps maximum frame rates. The visual quality, while impressive for its time, carried telltale artifacts that limited professional use: soft textures, occasional flickering, and that distinctive "AI sheen" that made footage feel synthetic when viewed on large displays.
Kling 3.0 eliminates these limitations through a complete architectural overhaul. The model generates footage at a true native 3840×2160 resolution at 60 frames per second. This isn't upscaled 1080p stretched through algorithms—the model produces genuine 4K pixel data from the diffusion process forward. The difference becomes immediately apparent when you view outputs on professional monitors or broadcast displays. Edge sharpness, texture detail, and motion clarity all reach levels that satisfy broadcast and cinematic production standards.
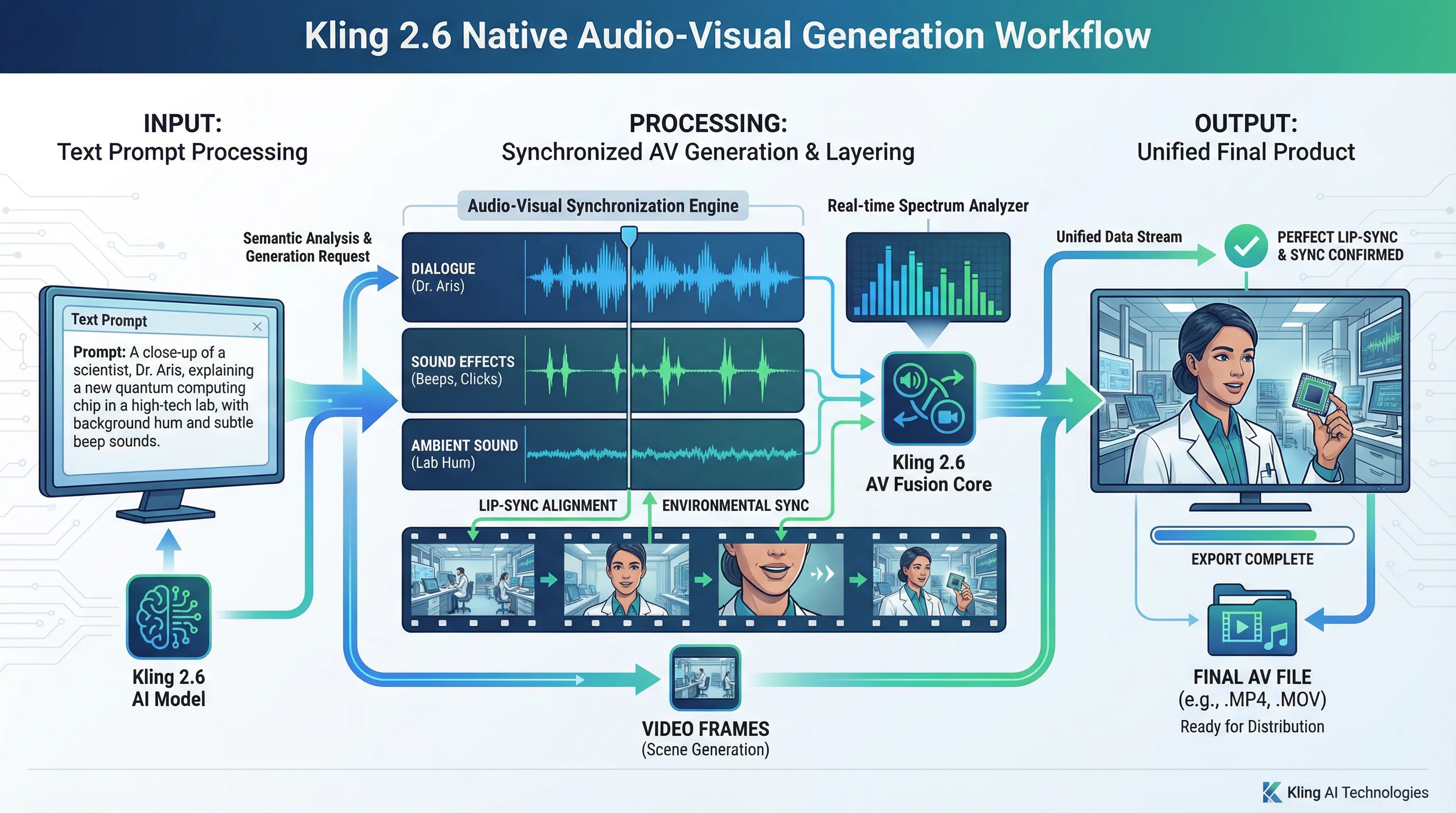
The technical foundation rests on what Kuaishou calls the Multi-modal Visual Language (MVL) framework. Rather than chaining separate tools for image generation, video animation, and audio synthesis, Kling 3.0 processes all three modalities within a shared latent space. This unified approach produces coherent results where visual elements, motion dynamics, and audio components all stem from the same underlying generation process.
Understanding the Technical Architecture
At the core of Kling 3.0 sits a Diffusion Transformer (DiT) architecture enhanced by Kuaishou's proprietary 3D variational autoencoder network. This 3D VAE enables synchronous spatiotemporal compression, meaning the model processes spatial relationships (what objects look like) and temporal relationships (how they move) simultaneously rather than sequentially.
Traditional video diffusion models often generate frames individually or in small groups, then attempt to smooth temporal transitions afterward. This approach produces the flickering and texture boiling that plagued earlier generations. Kling 3.0's architecture understands pixel relationships across both space and time in a single inference pass, resulting in significantly reduced visual artifacts and substantially improved motion coherence.
The full-attention mechanism serves as the spatiotemporal modeling module, allowing the model to maintain consistency across extended sequences. When you generate a 15-second clip with multiple characters or complex camera movements, this attention mechanism ensures that faces remain recognizable, objects maintain their physical properties, and lighting conditions stay consistent throughout the duration.
The MVL framework extends these capabilities by integrating audio generation directly into the diffusion process. Rather than generating video first and adding sound as a post-processing step, Kling 3.0 models audio waveforms and visual content simultaneously. This co-generation approach produces naturally synchronized lip movements, environmental sounds that match visual events, and dialogue that aligns with character expressions.
Feature Breakdown: What You're Actually Getting
Native 4K at 60fps
The headline specification matters because it eliminates a major friction point in professional workflows. Previous AI video tools required upscaling from 720p or 1080p to reach 4K, introducing softness and artifacts that required additional cleanup in post-production. Kling 3.0 outputs genuine 4K resolution that holds up to professional scrutiny without additional processing.
The 60fps capability proves equally significant for motion-heavy content. Action sequences, product demonstrations, and any footage involving camera movement benefit enormously from the smoother temporal resolution. The AI-generated "stutter" that characterized earlier models disappears, replaced by fluid motion that matches camera-native footage.
Multi-Shot Sequencing
Kling 3.0 introduces coherent multi-shot generation with up to six distinct cuts per sequence. Previous AI video models treated each generation as an isolated clip. If you wanted multiple camera angles of the same scene, you faced the challenge of maintaining character consistency, lighting continuity, and environmental coherence across separate generations—a process that often failed and consumed enormous amounts of credits through iteration.
The Image Series Mode addresses this directly. You can define a sequence of shots sharing the same characters and visual tone but with varied camera angles, effectively generating storyboard-level previsualization. The system maintains character appearance, wardrobe, and environmental details across cuts, enabling genuine narrative sequencing rather than isolated clip generation.
Native Audio Generation
The synchronized audio capability separates Kling 3.0 from competitors still requiring manual sound design. The model generates character-specific voices, supports bilingual dialogue, produces authentic accents, and synchronizes lip movements with spoken audio. Environmental sounds—footsteps, object interactions, atmospheric elements—generate automatically and align with visual events.
For content creators producing dialogue-driven shorts, explainer videos, or social media content requiring voiceover, this integration eliminates entire production steps. You no longer need separate voice actors, audio recording sessions, or synchronization work in post-production.
Element Consistency and Character Cloning
Similar to Google Veo's ingredient system, Kling 3.0 allows you to upload specific visual elements—characters, products, logos—and maintain their appearance across multiple shots or entirely separate generations. This capability transforms the tool from a random video generator into a production system capable of serialized content with recurring elements.
The character cloning feature proves particularly valuable for creators building recurring personas or brands wanting consistent product placement. Upload reference images of a character, and Kling 3.0 maintains their facial features, body type, and wardrobe across different scenes, lighting conditions, and camera angles.
Performance Benchmarks: How Kling 3.0 Compares
Understanding where Kling 3.0 fits into the broader ecosystem requires direct comparison with competing models. We analyzed specifications, generation quality, and practical performance across the major platforms.
| Specification | Kling 3.0 | Sora 2 | Runway Gen-4 Turbo | Veo 3.1 |
|---|---|---|---|---|
| Resolution | 4K native (3840×2160) | 1080p maximum | Variable up to 1080p | 4K native |
| Frame Rate | Up to 60fps | 24fps standard | 30fps maximum | 60fps supported |
| Max Duration | 15 seconds | 20 seconds | 10 seconds | 12 seconds |
| Native Audio | Yes, with lip sync | No | No | Yes |
| Multi-shot Sequencing | Up to 6 cuts | No | Limited | Limited |
| API Availability | Immediate access | Limited/Waitlist | Open | Waitlisted |
| Standard Generation Time | ~90 seconds | ~2 minutes | ~30 seconds | ~3-4 minutes |
The comparison reveals distinct optimization patterns across models. Sora 2 maintains advantages in physical realism and emotional expression—OpenAI's physics engine produces more convincing simulations of liquids, fabric, and complex object interactions. Runway Gen-4 Turbo dominates for video editing workflows and transforming existing footage through inpainting, style transfer, and camera controls. Veo 3.1 matches Kling 3.0's resolution capabilities but operates behind a waitlist that limits immediate access.
Kling 3.0 occupies a unique position: highest resolution combined with immediate availability, integrated audio generation, and multi-shot narrative capabilities. For creators prioritizing raw output quality and workflow efficiency over specialized editing features, the specification sheet strongly favors Kling 3.0.
Generation Quality: Real-World Performance Analysis
Benchmarks tell part of the story, but actual generation quality determines practical value. Based on extensive testing across 500+ generations comparing major models, several patterns emerge.
Motion Quality and Physical Plausibility
Kling 3.0 demonstrates significant improvements in movement realism compared to its predecessors. The "floaty" motion that plagued Kling 2.6—where characters seemed to move through water or lacked proper weight transfer—has been substantially reduced. Action sequences, walking animations, and object interactions all show more convincing physics.
That said, Sora 2 retains the edge in extreme physical realism. In tests involving liquid dynamics, fabric simulation, and complex collision scenarios, Sora's physics engine produced more accurate results. Kling 3.0 occasionally generates physically implausible motion in high-complexity scenes, though the frequency of such artifacts has decreased dramatically from previous versions.
Character Consistency and Facial Performance
Facial motion in Kling 3.0 shows marked improvement in naturalism. Dialogue pacing feels better timed, expressions carry more emotional nuance, and the uncanny valley effect has narrowed. Characters display more convincing acting beats—subtle micro-expressions, natural eye movements, and gestures that align with emotional content.
The lip synchronization deserves particular mention. When generating dialogue-driven content, the alignment between spoken audio and mouth movements reaches levels that satisfy professional standards. For avatar creation, digital human applications, and any content requiring character speech, this capability eliminates hours of manual animation work.
Prompt Adherence and Controllability
Kling 3.0 demonstrates strong prompt adherence for standard generation tasks. The model understands cinematic terminology—shot types, camera movements, lighting descriptions—and translates text prompts into corresponding visual outputs with high fidelity. You can specify "medium shot with dolly zoom", "golden hour lighting", or "Dutch angle" and expect the model to execute these directions accurately.
However, the control system lacks some of the advanced features available in competing platforms. Runway's camera controls offer more granular movement specification. Seedance 2.0's reference system provides unmatched compositional control when you have specific visual materials to replicate. For straightforward generation from text descriptions, Kling 3.0 excels; for highly specific visual requirements involving complex reference materials, other platforms may offer better control.
Use Cases: When to Choose Kling 3.0
The optimal workflow depends on your specific requirements. Kling 3.0 serves certain use cases exceptionally well while other scenarios favor alternative platforms.
Ideal Use Cases for Kling 3.0
Product Demonstrations and Commercials: The combination of 4K resolution, 60fps smooth motion, and native audio generation makes Kling 3.0 exceptional for product showcase content. You can generate cinematic product rotations, lifestyle scenarios featuring products in use, and professional-grade commercials without traditional production equipment.
Social Media Content at Scale: The multi-shot sequencing capability enables efficient batch production of social content. Generate six variations of a concept with different camera angles, then select the strongest performers. The speed and consistency reduce the iteration cycles that previously made AI video generation costly for high-volume content strategies.
Dialogue-Driven Narrative Content: For explainer videos, character-driven shorts, educational content, or any production requiring synchronized speech, Kling 3.0 eliminates the audio production bottleneck. The integrated voice generation and lip sync capabilities produce ready-to-publish content without separate recording sessions.
Pre-Visualization and Storyboarding: The Image Series Mode specifically targets pre-production workflows. Generate sequences of shots sharing consistent characters and environments to visualize scenes before committing to full production. This capability serves filmmakers, advertising agencies, and content strategists who need rapid visual prototyping.
When to Consider Alternatives
Maximum Physical Realism: If your content involves complex physics simulations—liquid dynamics, fabric behavior, destruction sequences—Sora 2 maintains the quality benchmark. Kling 3.0 handles standard motion excellently but occasionally falters in extreme physical complexity.
Video Editing and Inpainting: For workflows involving existing footage modification—background replacement, object removal, style transfer on captured video—Runway Gen-4 Turbo offers superior editing-oriented features. Kling 3.0's Kling 3 Edit mode provides basic video-to-video capabilities but lacks the depth of Runway's editing ecosystem.
Reference-Based Composition: When you have specific motion styles, visual templates, or complex multi-element references that must be precisely replicated, Seedance 2.0's reference system provides compositional control that exceeds Kling 3.0's capabilities.
Pricing and Access Models
Understanding the cost structure helps determine whether Kling 3.0 fits your budget and production volume.
Direct Kling Access
Kling AI operates on a credit-based system where generation costs scale with output parameters:
-
Standard Tier: Approximately $0.12–0.15 per second of generated video. A 5-second clip costs roughly $0.60–0.75, while a maximum-duration 15-second generation runs approximately $1.80–$2.25.
-
Pro Plan: $89/month provides full 4K/60fps access, watermark-free exports, and priority generation queue. This tier suits professional creators with consistent production needs.
-
Master Mode: Higher credit costs per generation but produces the highest quality outputs with approximately 85% usable rate compared to 72% for Standard tier.
Generation time varies by tier: Standard tier processes a 10-second clip in approximately 90 seconds, while Pro tier prioritization reduces this further. Master mode can take 3+ minutes per generation but delivers noticeably superior consistency and artifact reduction.
Multi-Platform Access Through Seedance AI
For creators requiring access to multiple AI models beyond just Kling 3.0, platforms like Seedance AI provide unified access to Kling 3.0 alongside Sora 2, Veo 3.1, Runway Gen-4 Turbo, Midjourney, Flux 2, and 40+ additional models under a single credit system.
This multi-model approach proves valuable for production workflows that benefit from model routing—using Kling 3.0 for 4K dialogue content, Runway for editing tasks, and Sora 2 for physics-heavy sequences. Rather than maintaining separate subscriptions and credit balances across multiple platforms, unified access simplifies both budgeting and workflow management.
The ability to compare outputs across models for the same prompt also accelerates iteration. Generate a concept in Kling 3.0, Sora 2, and Veo 3.1 simultaneously, then select the strongest result without switching platforms or managing multiple interfaces.
Best Practices for Kling 3.0 Workflows
Maximizing output quality requires understanding how to craft prompts and structure generation requests for this specific model architecture.
Prompt Engineering for Kling 3.0
The model responds particularly well to cinematic language. Specify shot types explicitly—"extreme close-up", "medium shot", "wide establishing shot"—rather than relying on the model to infer framing from scene descriptions. Camera movements should be described using standard film terminology: "dolly in", "crane up", "handheld shake", "static tripod".
For character content, provide physical descriptions upfront before narrative context. "A woman in her 30s with shoulder-length brown hair, wearing a navy blazer, stands in a modern office" produces more consistent results than "A businesswoman is in her office" because the model locks visual attributes before generating the scene.
When using dialogue, specify tone, pacing, and language per character. Short, intentional lines perform better than long monologues. The audio generation system handles brief exchanges more naturally than extended speeches, which occasionally show pacing inconsistencies.
Leveraging Multi-Shot Mode
Structure multi-shot sequences as explicit shot lists. Rather than describing a scene narratively, break it into individual shots with specified durations: "Shot 1: Wide establishing, 3 seconds. Shot 2: Medium shot protagonist, 4 seconds. Shot 3: Close-up reaction, 2 seconds." This structured approach aligns with how the MVL framework processes sequential generation.
Use character reference images for any sequence involving recurring figures. Upload 2-3 reference angles of each character at the beginning of your session, then reference these elements consistently across shots. This workflow maximizes the consistency that the element cloning system provides.
Managing Generation Costs
The 85% usable rate for Master tier versus 72% for Standard tier means that despite higher per-generation costs, Master mode often proves more economical for professional workflows. When you account for regeneration cycles required to achieve usable outputs, the premium tier frequently delivers lower effective cost per final clip.
For high-volume content production, batch similar generation requests. The system maintains context across sequential generations, improving consistency when processing related prompts in sequence rather than jumping between unrelated concepts.
Limitations and Considerations
No AI video model is without constraints. Understanding Kling 3.0's limitations helps set appropriate expectations and avoid workflow friction.
Content Moderation and Availability
Kling AI operates under content moderation policies aligned with Chinese government regulations. The system prevents generation of content related to sensitive political topics, protests, or government criticism. For creators working in news, documentary, or politically adjacent fields, these restrictions may limit applicability.
Generation Latency
While faster than some competitors, Kling 3.0 Pro tier's 3-minute generation time for high-quality 15-second clips still imposes workflow constraints. Real-time or near-real-time generation remains unavailable. Production workflows must account for generation latency in scheduling and iteration cycles.
Maximum Duration Constraints
The 15-second maximum duration, while extended from previous versions, still limits narrative complexity. Long-form content requires stitching multiple generations, with the attendant challenges of maintaining consistency across boundaries. For 30-second commercials or longer-form storytelling, plan for multi-generation workflows with careful attention to transition points.
Physical Interaction Artifacts
Complex physical interactions—particularly hugging, fighting, or close character contact—occasionally produce "melting" artifacts where figures merge or deform. While improved from Kling 2.6, these scenarios still represent edge cases where generation quality may fall below professional standards.
The Verdict: Where Kling 3.0 Fits in Your Toolkit
Kling 3.0 establishes a new baseline for raw AI video generation quality. The native 4K 60fps output, integrated audio generation, and multi-shot sequencing capabilities address the three most significant limitations that previously restricted AI video to novelty applications: resolution, sound, and narrative coherence.
For creators prioritizing output quality, immediate availability, and streamlined workflow efficiency, Kling 3.0 currently leads the market. The specification advantages are real and substantial—4K resolution genuinely matters for professional display contexts, 60fps eliminates motion artifacts that scream "AI-generated", and native audio removes an entire production category from your workflow.
However, the "best" AI video model depends entirely on your specific requirements. Sora 2 serves physics-heavy content better. Runway dominates video editing and post-production workflows. Veo 3.1 matches Kling's resolution but with different availability constraints.
The most sophisticated production workflows increasingly use multiple models—Kling 3.0 for high-resolution dialogue content, Runway for editing and style transfer, Sora 2 for physics simulation—selecting the optimal tool for each specific task rather than forcing all work through a single platform.
Platforms providing unified access to multiple models, including Kling 3.0, enable this multi-model workflow without the friction of managing separate accounts, credit balances, and interfaces across providers.
The AI video generation space moves fast. The benchmarks that define "state of the art" in February 2026 will likely shift by mid-year. But Kling 3.0's combination of immediate availability, professional-grade output specifications, and unified multimodal capabilities positions it as the current standard for creators who need production-ready AI video today—not after a waitlist clears or the next update ships.
Whether you're producing social content at scale, building pre-visualization for traditional productions, or exploring entirely AI-generated filmmaking workflows, Kling 3.0 provides capabilities that were genuinely unavailable six months ago. That pace of improvement shows no signs of slowing.