The AI video generation landscape has reached a critical inflection point in early 2026. After years of incremental improvements, we now have production-ready models that generate synchronized audio alongside video, maintain character consistency across shots, and follow complex creative directions with remarkable precision. Among the leading contenders, two models stand out for their advanced capabilities and production readiness: Seedance 2 from ByteDance and Wan 2.6 from Alibaba's ecosystem.
This comprehensive comparison examines both models across technical specifications, feature sets, real-world performance, and practical applications. We've analyzed benchmark data, community feedback, and hands-on testing results to provide creators, marketers, and production teams with the information needed to make informed decisions about which model best serves their specific needs.
Executive Summary: Key Differences at a Glance
Before diving into detailed analysis, here's what separates these two industry-leading models:
Seedance 2 excels at multimodal reference control, cinematic storytelling, and natural audio-visual synchronization. The model accepts up to 12 different input assets simultaneously—including images, videos, audio files, and text prompts—and synthesizes them into coherent narrative sequences. This makes Seedance 2 particularly powerful for complex creative projects that require precise control over multiple visual and audio elements.
Wan 2.6 prioritizes structured production workflows, repeatability, and practical format support through three specialized generation pathways: text-to-video (T2V), image-to-video (I2V), and reference-to-video (R2V). Each pathway is optimized for specific use cases, providing clear production constraints and predictable outputs. Wan 2.6 also benefits from open-source availability and extensive API integration options.
Technical Specifications: Foundation for Performance
Understanding the technical capabilities of each model provides essential context for evaluating their practical applications.
Resolution and Output Quality
Both models deliver professional-grade output suitable for commercial distribution:
| Specification | Seedance 2 | Wan 2.6 |
|---|---|---|
| Maximum Resolution | Up to 1080p | Up to 1080p |
| Frame Rate | 24 fps | 24 fps |
| Duration Range | 4-15 seconds | 5-15 seconds |
| Aspect Ratios | 16:9, 9:16, 4:3, 3:4, 21:9, 1:1 | 16:9, 9:16, 1:1 (varies by mode) |
| Native Audio | Yes, synchronized | Yes, synchronized |
| Multi-shot Capability | Yes, with natural transitions | Yes, with scene segmentation |
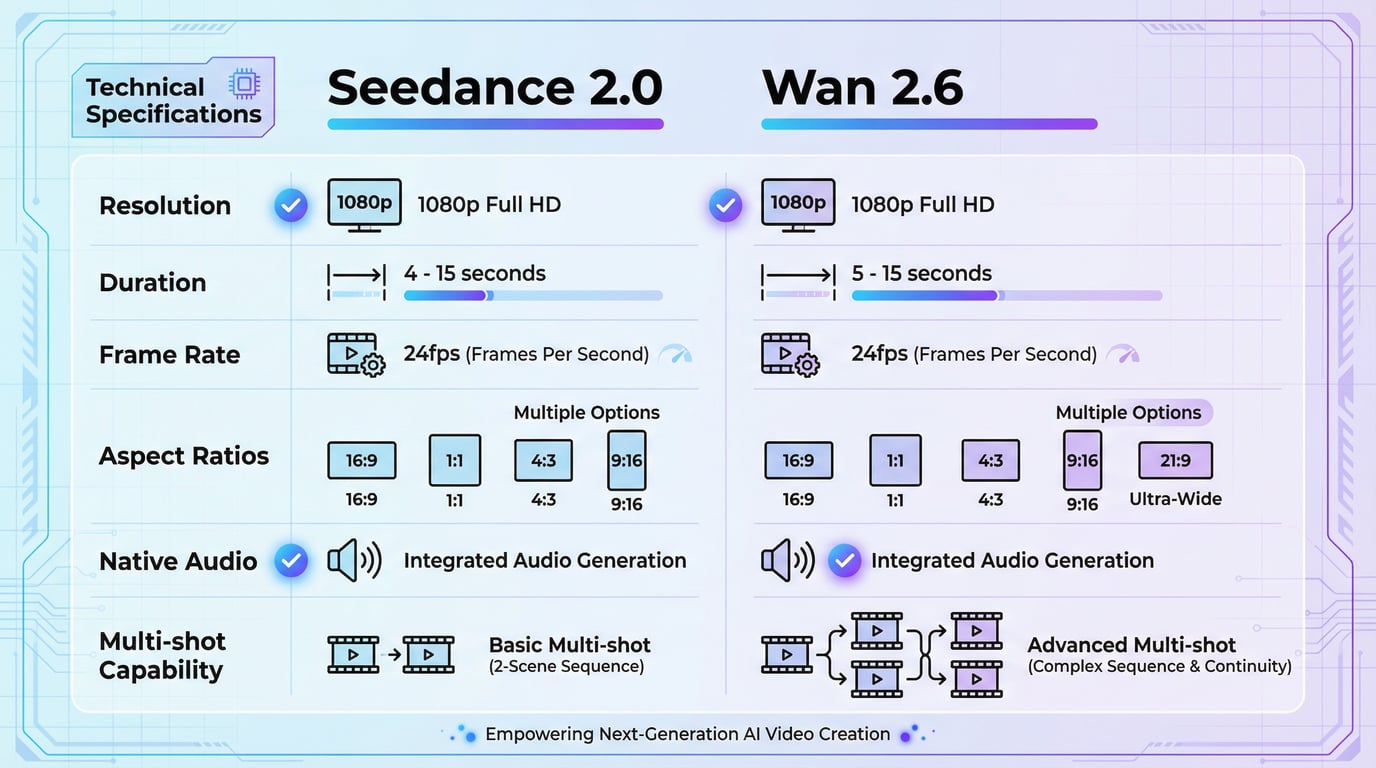
Both models output at 1080p resolution with 24fps frame rates, which represents the current industry standard for AI-generated video content. While some competing models like Kling 3.0 have pushed into native 4K territory, the 1080p output from both Seedance 2 and Wan 2.6 remains production-ready for most commercial applications including social media, advertising, and web content.
Architecture and Model Design
The architectural differences between these models significantly impact their behavior and optimal use cases.
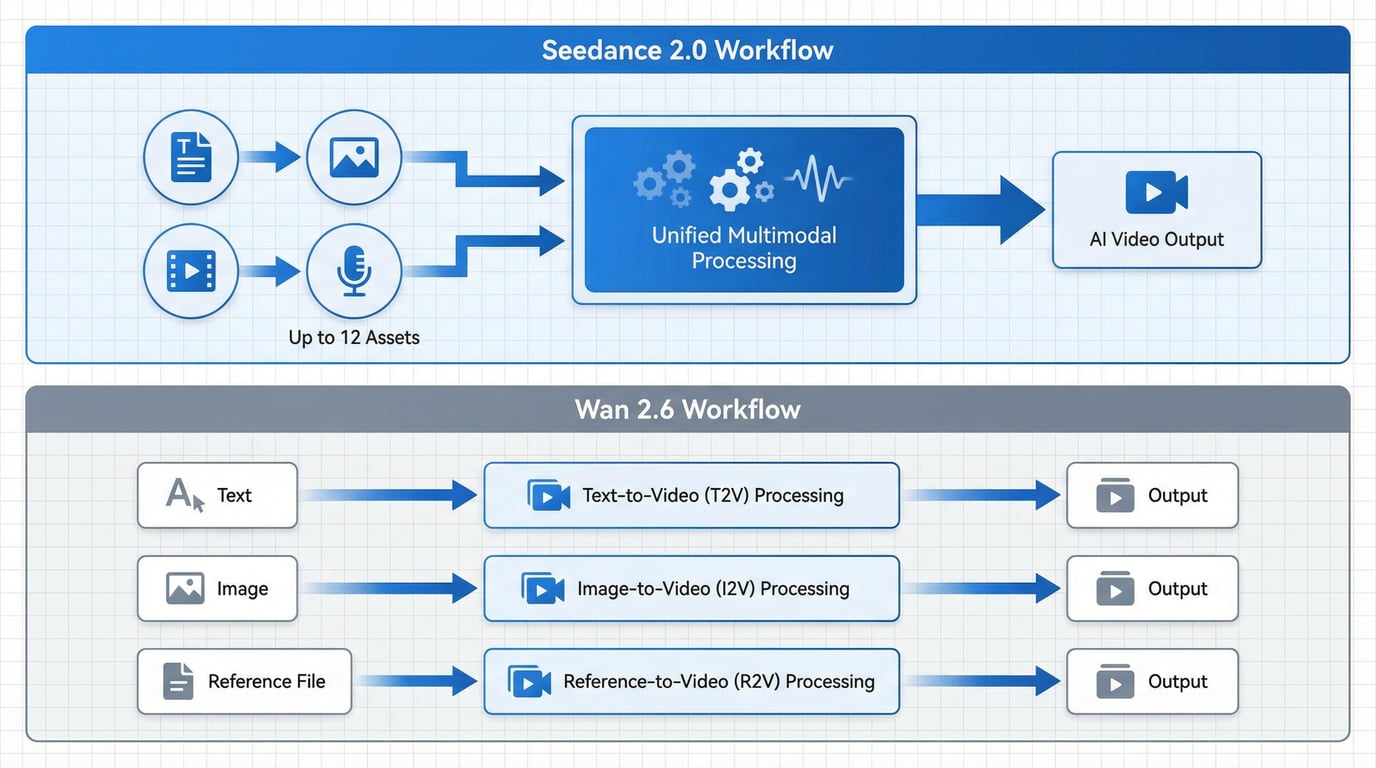
Seedance 2 employs a unified multimodal audio-video joint generation architecture. This design allows the model to process text, images, video references, and audio inputs simultaneously within a single generation pipeline. The dual-branch architecture specifically enhances lip-sync accuracy and micro-expression rendering, making it particularly effective for dialogue-driven content and emotional performances.
Wan 2.6 utilizes a modular architecture with three distinct generation pathways. Each pathway—T2V, I2V, and R2V—has been independently optimized for its specific input type. This separation provides clearer production constraints and more predictable behavior, which benefits teams that need consistent, repeatable results across large-scale content production. The R2V pathway, in particular, represents a significant advancement for maintaining character consistency across multiple shots.
Feature Comparison: Capabilities That Matter
Multimodal Input Handling
This represents one of the most significant differentiators between the two models.
Seedance 2 supports comprehensive multimodal input with the ability to accept up to 12 different assets in a single generation request. Users can simultaneously provide reference images for visual style, video clips for motion and camera work, audio tracks for rhythm and pacing, and detailed text prompts for narrative guidance. The model uses a natural language @ mention system to specify how each uploaded asset should be utilized in the final output.
This multimodal capability enables unprecedented creative control. For example, a creator can reference a specific film's cinematography through a video clip, apply the color grading from a photograph, sync the pacing to a music track, and guide the narrative with text—all in a single generation. This level of integrated control was previously impossible in generative video.
Wan 2.6 takes a more structured approach with three specialized endpoints. The text-to-video pathway handles pure prompt-based generation with enhanced LLM-based prompt expansion that preserves narrative context across shot transitions. The image-to-video pathway focuses on motion coherence when animating still images. The reference-to-video pathway specifically addresses character consistency, allowing creators to maintain stable subject identity across multiple generated clips.
While Wan 2.6's approach offers less simultaneous input flexibility than Seedance 2, the specialized pathways provide clearer guidance for specific production scenarios and more predictable outputs.
Audio-Visual Synchronization
Both models generate native audio alongside video, eliminating the need for post-production audio work—a significant workflow improvement over earlier AI video models.
Seedance 2 demonstrates exceptional strength in lip-sync accuracy and emotional audio performance. The dual-branch architecture processes audio and video in parallel, enabling frame-accurate synchronization of dialogue, facial expressions, and mouth movements. Community feedback consistently highlights "Seedance moments" where the audio-visual synchronization achieves near-photorealistic quality, particularly in close-up dialogue scenes and emotional performances.
The model generates dialogue, ambient soundscapes, and real-time sound effects that match visual content frame by frame. This integrated approach produces natural speech-driven animation that feels cinematic rather than synthetic, making it particularly valuable for narrative content, character-driven stories, and any application requiring believable human interaction.
Wan 2.6 also provides native audio-visual synchronization with precise lip-sync capabilities. The model integrates lip-sync and dialogue timing at the generation level, producing natural speech-driven animation suitable for professional applications. While Wan 2.6 performs well in this area, comparative testing suggests it excels more in advertising and structured content scenarios rather than the extreme close-up dialogue situations where Seedance 2 particularly shines.
Motion Control and Physics Accuracy
Realistic motion and physics simulation separate professional-grade AI video from obvious synthetic content.
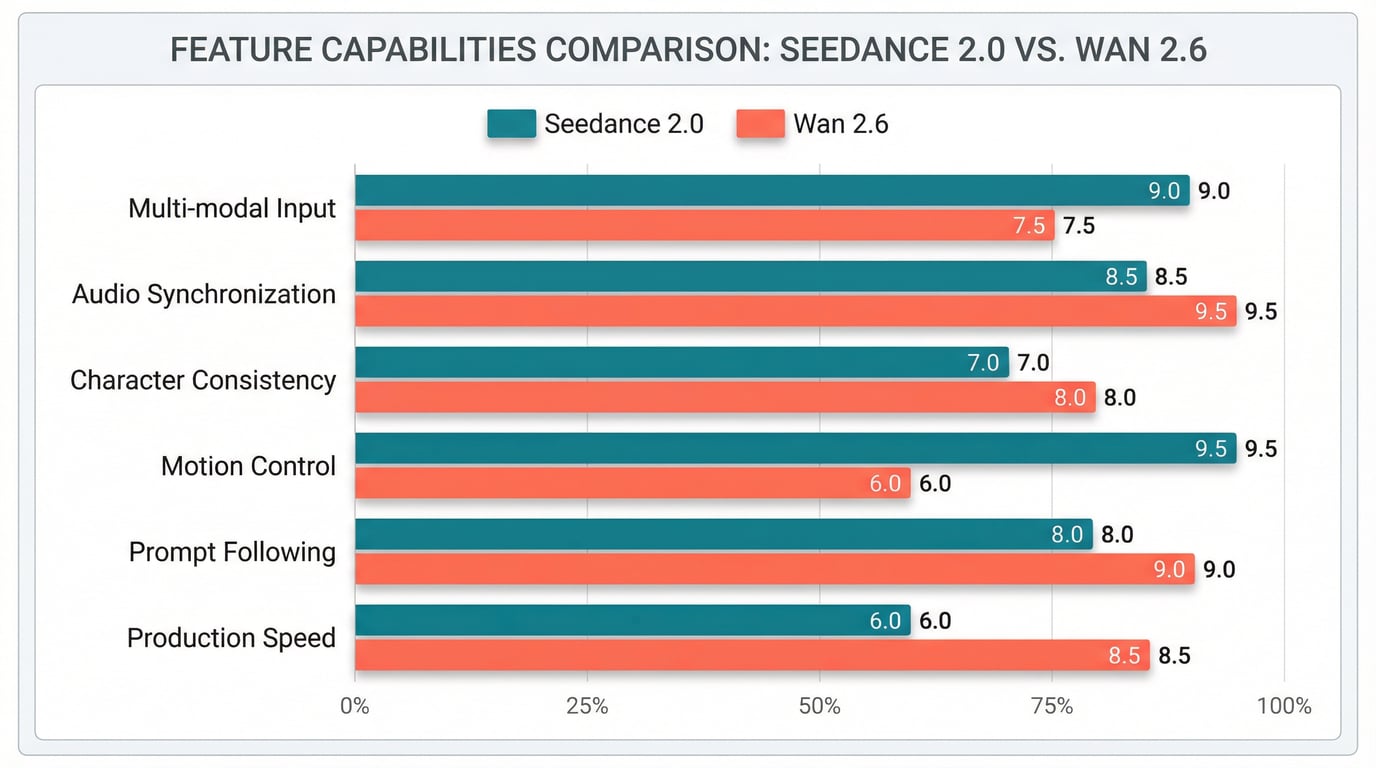
Seedance 2 demonstrates strong physics accuracy with objects falling, colliding, and interacting according to real-world rules. The model handles complex camera work including dolly zooms, rack focuses, tracking shots, POV switches, and smooth handheld movement. Action sequences—including fight scenes, vehicle chases, explosions, and falling debris—render with convincing physics and motion coherence.
Community comparisons note that Seedance handles realistic scenarios particularly well, with one analysis describing it as "a competent documentary director" where realism is a traditional strength. The model excels at natural body movement and expressions, though some users report occasional character duplication in complex scenes.
Wan 2.6 provides enhanced motion coherence compared to its predecessor Wan 2.5, with particular strength in maintaining narrative continuity across multi-shot sequences. The model's prompt handling has been specifically improved to preserve context during scene transitions, reducing the need for manual prompt engineering when creating multi-scene sequences.
Character and Visual Consistency
Maintaining consistent character appearance across shots and scenes represents a critical challenge in AI video generation.
Seedance 2 features significantly improved consistency for faces, clothing, text, scenes, and visual styles. The model maintains stable character appearance across frames and shots, addressing common AI video problems like character drift, style inconsistency, and detail loss. The multimodal reference system allows creators to lock in specific character appearances through reference images while varying other aspects of the scene.
Wan 2.6 specifically addresses consistency challenges through its reference-to-video (R2V) pathway. This specialized mode focuses on subject consistency, allowing creators to maintain character identity across multiple generated clips. The R2V pathway represents one of Wan 2.6's most significant improvements over Wan 2.5, directly addressing one of the most critical pain points that prevented wider adoption of AI video tools in professional production environments.
Prompt Following and Instruction Adherence
The ability to accurately interpret and execute complex creative directions determines how much manual iteration is required to achieve desired results.
Seedance 2 emphasizes detailed instruction following, particularly for scenes requiring multiple subjects, actions, and camera cues simultaneously. The model understands and executes complex prompts with precision, and the natural language control system allows creators to describe reference usage intuitively. The more detailed the prompt—including specific camera angles, timing, and reference instructions—the more precise the output becomes.
Wan 2.6 delivers stronger instruction following compared to Wan 2.5, with enhanced prompt handling that better preserves narrative context across shot transitions. The LLM-based prompt expansion system has been refined to reduce manual prompt engineering requirements for multi-scene sequences. This improvement makes Wan 2.6 more accessible to users who may not have extensive experience crafting optimal AI prompts.
Performance Benchmarks: Real-World Testing Results
Community testing and benchmark comparisons provide valuable insights into how these models perform across various scenarios.
Artificial Analysis Rankings
On Artificial Analysis, a platform that ranks video generators through public voting rather than internal metrics, Seedance 1.0 achieved #1 rankings for both text-to-video and image-to-video generation, surpassing Veo 3, Kling 2.0, OpenAI's Sora, Runway Gen4, and Wan 2.1. While these rankings predate the Wan 2.6 release, they establish Seedance's strong competitive position in the broader AI video landscape.
Scenario-Based Performance
Comparative testing across specific scenarios reveals distinct strengths:
Crowd Scenes and Large-Scale Motion: Seedance demonstrates strong performance in managing realistic crowd behavior and large-scale motion, though it occasionally adds slight camera drift that can be corrected through prompt tuning. Wan 2.6 performs acceptably in smaller crowd scenarios but shows artifacts in dense scenes.
Action and Effects: For dynamic action sequences and visual effects like explosions or fire, Seedance produces strong smoke simulation and timing, though lighting can occasionally be over-bright. Wan 2.6 shows capability in structured action sequences but may exhibit instability in extreme scenarios.
Character Animation: Seedance excels at natural body movement and facial expressions with exceptional lip-sync quality, particularly in dialogue-heavy content. Wan 2.6 provides solid character animation suitable for advertising and structured content, with the R2V pathway specifically addressing character consistency needs.
Generation Speed
Seedance 2 is reported to be 30% faster than its predecessor Seedance 1.5, with generation typically completing within minutes depending on complexity and duration. Community feedback identifies Seedance 1.5 as a speed leader among major models, suggesting Seedance 2 maintains competitive generation times.
Wan 2.6 achieves fast generation speeds, particularly when accessed through optimized platforms. Generation typically takes 1-3 minutes depending on video length and complexity. The structured pathway approach may contribute to predictable processing times across different generation modes.
Practical Applications: Which Model for Which Use Case
Selecting the optimal model depends on specific production requirements, content types, and workflow constraints.
Seedance 2 Excels At:
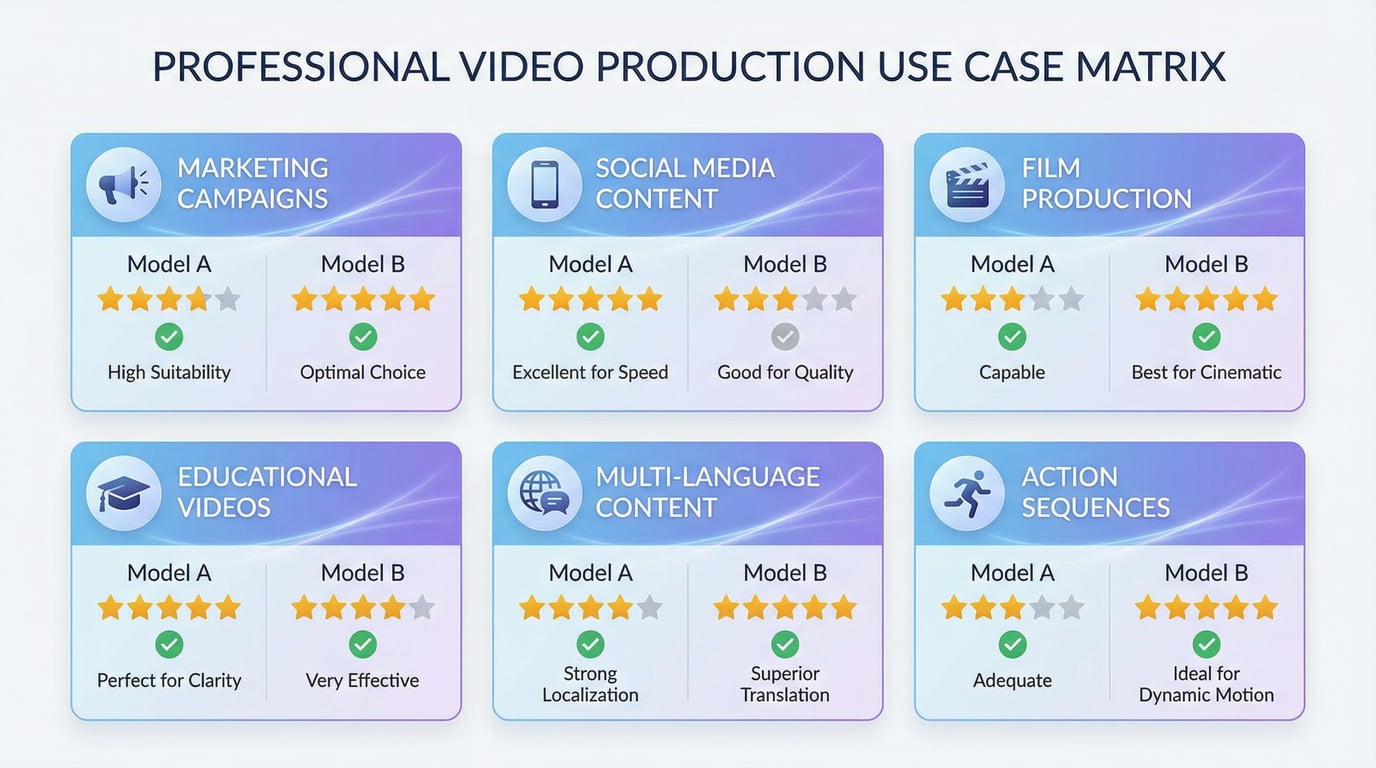
Narrative and Cinematic Content: The multimodal reference system and exceptional audio-visual synchronization make Seedance 2 ideal for storytelling applications that require emotional depth, character-driven narratives, and cinematic quality. Filmmakers creating storyboards, proof-of-concept sequences, or atmospheric scenes benefit from the model's ability to synthesize multiple creative references into coherent visual narratives.
Dialogue-Heavy Content: The dual-branch architecture's superior lip-sync accuracy and micro-expression rendering make Seedance 2 the preferred choice for content featuring human dialogue, emotional performances, and close-up character interactions. Educational content creators, explainer video producers, and anyone creating conversational content will find significant value in this capability.
Complex Multi-Reference Projects: When a project requires synthesizing inspiration from multiple sources—matching the cinematography of one reference, the color palette of another, the pacing of a music track, and a detailed narrative prompt—Seedance 2's ability to accept up to 12 simultaneous input assets provides unmatched creative control.
Realistic Documentary-Style Content: Community testing consistently identifies realism as a traditional Seedance strength, making it particularly suitable for documentary-style content, realistic scenarios, and applications where believability and natural motion are paramount.
Wan 2.6 Excels At:
Structured Marketing and Advertising: The three specialized generation pathways provide clear production constraints and repeatable workflows ideal for marketing teams producing consistent brand content. The structured approach ensures predictable outputs across campaigns, making Wan 2.6 a safer default for repeatable production environments.
Character Consistency Requirements: The reference-to-video pathway specifically addresses the challenge of maintaining character identity across multiple clips. Brands creating mascot content, series with recurring characters, or any application requiring consistent character appearance across multiple videos will benefit from this specialized capability.
Multi-Shot Narrative Campaigns: Wan 2.6's strong multi-shot narrative capabilities support coherent storytelling across scenes, making it suitable for brand films, educational content series, and structured video campaigns that require maintaining narrative continuity across multiple segments.
Developer Integration and API Workflows: Wan 2.6's open-source availability and extensive API integration options make it particularly attractive for developers building video generation into applications, platforms requiring on-premise deployment, and teams needing to customize model behavior for specific use cases.
Budget-Conscious Production: Wan 2.6's open-source nature and competitive API pricing make it an economical choice for high-volume production workflows where cost per video is a significant consideration.
Accessing the Models: Platform Availability
Both models are accessible through multiple platforms, though availability varies by region and access method.
Seedance 2 is currently available in China with global rollout expected in Q2 2026. The model can be accessed through various API providers and platforms that have integrated ByteDance's video generation capabilities. For creators and businesses seeking immediate access to Seedance 2's advanced capabilities, Seedance 2.0 provides a convenient entry point to experience the model's multimodal generation features.
Wan 2.6 benefits from broader availability through its open-source nature and extensive platform integration. The model is accessible through multiple API providers, developer platforms, and third-party integrations. Creators can access Wan 2.6 through Wan 2.6, which offers streamlined access to all three generation pathways (T2V, I2V, and R2V) in a unified interface.
The platform at SeaDanceAI provides access to multiple cutting-edge video and image generation models, offering creators the flexibility to choose the optimal model for each specific project without managing multiple separate integrations. This unified access point simplifies workflow management for teams working across diverse content types and production requirements.
The Broader Competitive Landscape
While this comparison focuses on Seedance 2 and Wan 2.6, understanding their position relative to other major models provides valuable context.
Kling 3.0 from Kuaishou offers native 4K at 60fps with built-in multi-shot storyboarding, representing the highest resolution option currently available. However, this comes at a premium price point and may be overkill for many production scenarios where 1080p output is sufficient.
Veo 3.1 from Google DeepMind leads in comprehensive audio packages among closed models, with dialogue, foley, ambient sound, and music awareness in a single generation. Veo 3.1 also offers true 4K output, though access remains limited through Google's controlled rollout.
Sora 2 from OpenAI delivers exceptional physics accuracy and comprehensive audio generation, setting a quality ceiling in many dimensions. However, access remains restricted, and pricing has not been publicly disclosed for commercial use.
In this competitive landscape, Seedance 2 and Wan 2.6 distinguish themselves through immediate practical availability, production-ready quality, and clear value propositions for specific use cases. Neither attempts to be the best at every dimension; instead, each excels in particular areas that align with distinct production needs.
Decision Framework: Choosing Your Model
Rather than declaring a single "winner," the mature AI video generation market of 2026 requires matching model strengths to specific production requirements.
Choose Seedance 2 when:
-
Audio-visual synchronization quality is critical
-
Your project requires synthesizing multiple creative references
-
Dialogue, emotion, and character performance are central to your content
-
Cinematic quality and atmospheric storytelling are priorities
-
You need the highest quality lip-sync and micro-expressions
-
Realistic, documentary-style content is your focus
Choose Wan 2.6 when:
-
Repeatable, consistent production workflows are essential
-
Character consistency across multiple clips is required
-
You're producing structured marketing or advertising content
-
Developer integration and API flexibility are priorities
-
Budget constraints favor open-source options
-
Your team values clear production pathways and predictable outputs
Consider using both when:
-
You're producing diverse content types that play to each model's strengths
-
You want to A/B test different approaches to the same creative brief
-
Your production volume justifies maintaining multiple tool integrations
-
Different team members have different skill levels and workflow preferences
The Future of AI Video Generation
The rapid advancement from Seedance 1.0 to Seedance 2 and from Wan 2.5 to Wan 2.6 demonstrates the accelerating pace of innovation in AI video generation. Several trends are emerging that will shape the next generation of these tools:
Resolution and frame rate improvements continue pushing toward 4K and 60fps as standard outputs rather than premium features. While current 1080p/24fps output serves most production needs, the trajectory is clear.
Extended duration capabilities are expanding beyond the current 15-second maximum. Longer-form content generation remains challenging due to computational requirements and consistency maintenance, but incremental improvements are arriving with each model iteration.
Enhanced control interfaces are evolving beyond text prompts and reference images toward more intuitive creative direction systems. Seedance 2's natural language @ mention system represents one approach; future iterations may incorporate even more sophisticated control mechanisms.
Production workflow integration is becoming increasingly important as these tools move from experimental novelty to essential production infrastructure. API reliability, batch processing capabilities, and integration with existing creative software will differentiate professional-grade tools from consumer applications.
Conclusion: Production-Ready AI Video Has Arrived
The comparison between Seedance 2 and Wan 2.6 reveals a fundamental truth about the current state of AI video generation: we've moved beyond the question of whether AI can create professional video to the more nuanced question of which specialized tool best serves specific creative needs.
Seedance 2 represents the cutting edge of multimodal creative control and cinematic quality, particularly excelling in audio-visual synchronization, emotional performance, and complex reference synthesis. Its unified architecture and ability to process up to 12 simultaneous input assets provide unmatched creative flexibility for narrative and character-driven content.
Wan 2.6 delivers structured, repeatable production workflows through specialized generation pathways optimized for specific use cases. Its reference-to-video capability addresses critical character consistency needs, while its open-source nature and extensive API integration options make it particularly attractive for developers and budget-conscious production teams.
Neither model is universally superior; each excels in dimensions that matter for different production scenarios. The mature approach is to understand these strengths and match the right tool to each specific project.
For creators, marketers, and production teams navigating this landscape, the practical recommendation is clear: experiment with both models on representative content from your actual production pipeline. The differences in output quality, workflow efficiency, and creative control will become apparent quickly, allowing you to make informed decisions based on real results rather than specifications alone.
The AI video generation revolution is no longer coming—it's here. Tools like Seedance 2 and Wan 2.6 are already producing content that appears in commercial advertising, social media campaigns, educational materials, and creative projects worldwide. The question is no longer whether to adopt these tools, but how to integrate them most effectively into your creative workflow.
Access both models through unified platforms like Seedance 2.0 and Wan 2.6 to experience their capabilities firsthand and discover which best serves your specific creative vision.


