AI 视频生成领域在 2026 年初达到了一个关键的拐点。经过多年的增量改进,我们现在拥有了能够随视频生成同步音频、跨镜头保持角色一致性,并能以惊人精度遵循复杂创意指令的生产级模型。在领先的竞争者中,有两款模型因其先进的能力和生产就绪度脱颖而出:字节跳动的 Seedance 2 和阿里巴巴生态系统的 Wan 2.6。
这份全面的对比分析了这两款模型在技术规格、功能特性、真实世界表现以及实际应用方面的差异。我们分析了基准测试数据、社区反馈和实测结果,旨在为创作者、营销人员和制作团队提供信息,帮助他们根据特定需求做出明智的决策。
执行摘要:核心差异一览
在深入详细分析之前,先来看看这两款行业领先模型的不同之处:
Seedance 2 擅长多模态参考控制、电影感叙事和自然的视听同步。该模型可同时接受多达 12 种不同的输入资产(包括图像、视频、音频文件和文本提示),并将其合成为连贯的叙事序列。这使得 Seedance 2 在需要精确控制多种视觉和音频元素的复杂创意项目中表现尤为强大。
Wan 2.6 侧重于结构化的生产工作流、可重复性和实用的格式支持。它提供三条专门的生成路径:文本转视频(T2V)、图像转视频(I2V)和参考转视频(R2V)。每条路径都针对特定用例进行了优化,提供了明确的生产约束和可预测的输出。Wan 2.6 还受益于开源可用性和广泛的 API 集成选项。
技术规格:性能的基石
了解每款模型的技术能力为评估其在实际中的应用提供了重要背景。
分辨率与输出质量
两款模型均能提供适合商业发行的专业级输出:
| 技术规格 | Seedance 2 | Wan 2.6 |
|---|---|---|
| 最高分辨率 | 最高 1080p | 最高 1080p |
| 帧率 | 24 fps | 24 fps |
| 时长范围 | 4-15 秒 | 5-15 秒 |
| 纵横比 | 16:9, 9:16, 4:3, 3:4, 21:9, 1:1 | 16:9, 9:16, 1:1 (依模式而定) |
| 原生音频 | 是,已同步 | 是,已同步 |
| 多镜头能力 | 是,具有自然过渡 | 是,具有镜头分割 |
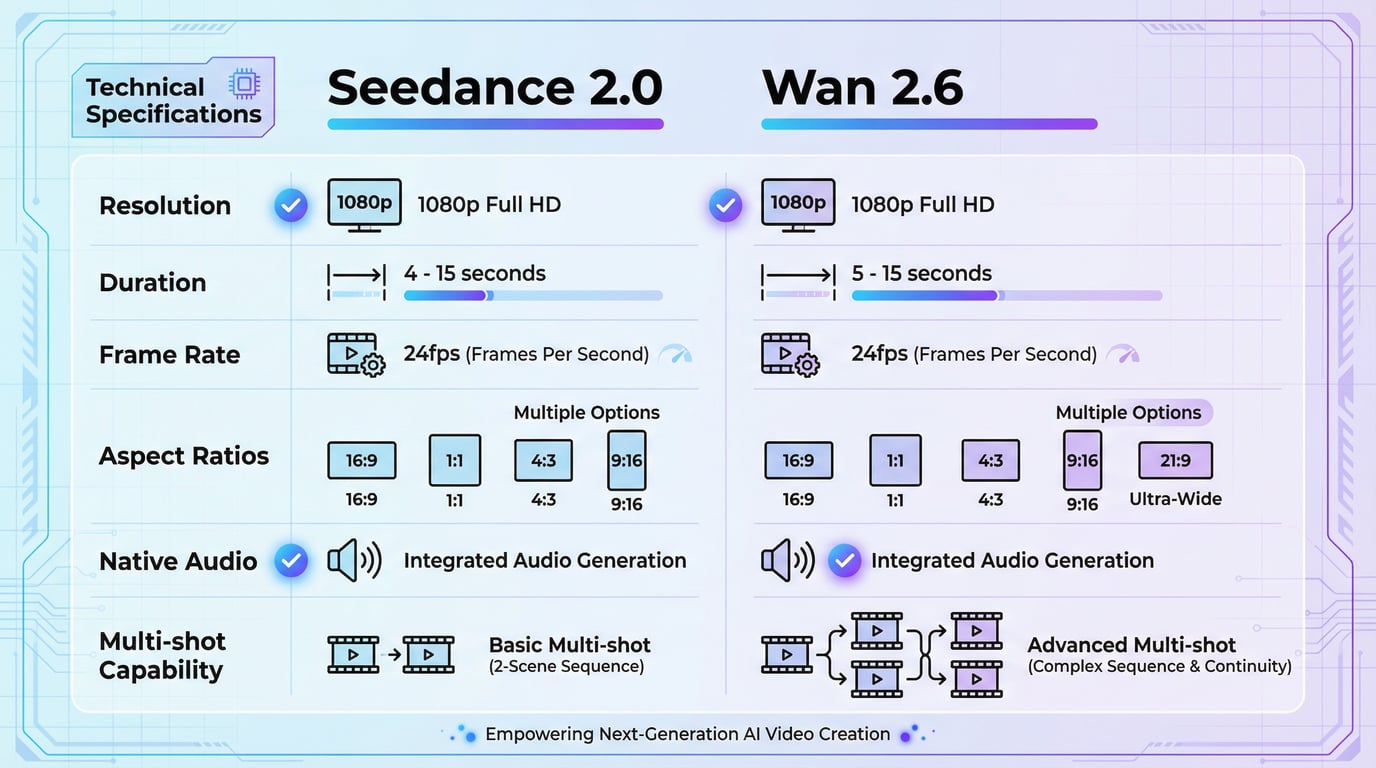
两款模型均以 1080p 分辨率和 24fps 帧率输出,这代表了当前 AI 生成视频内容的行业标准。虽然 Kling 3.0 等竞争模型已步入原生 4K 领域,但 Seedance 2 和 Wan 2.6 的 1080p 输出对于大多数商业应用(包括社交媒体、广告和网络内容)来说依然具备生产就绪性。
架构与模型设计
这两款模型在架构上的差异显著影响了它们的表现和最佳用例。
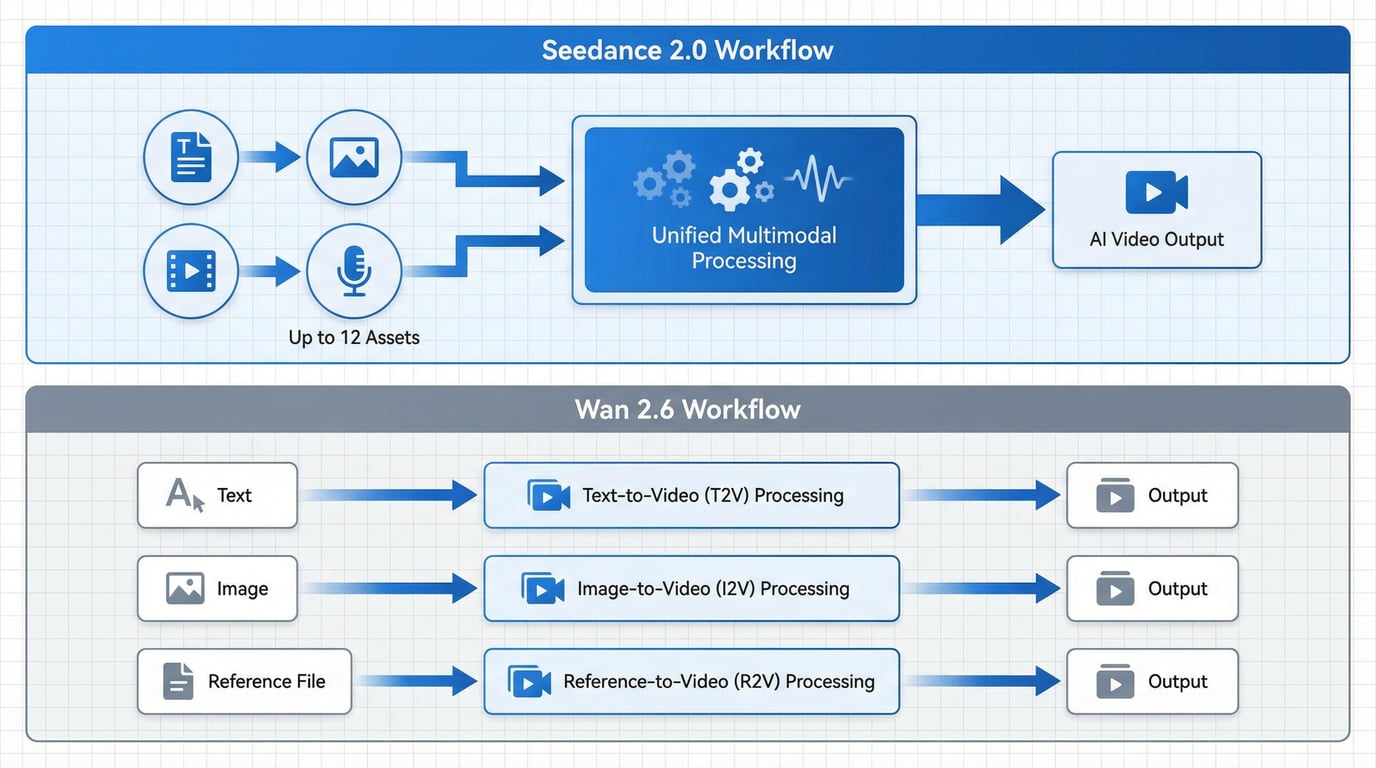
Seedance 2 采用了统一的多模态视听联合生成架构。这种设计允许模型在单个生成流程中同时处理文本、图像、视频参考和音频输入。双分支架构专门增强了对口型精度和微表情渲染,使其在对话驱动的内容和情感表演中表现尤为出色。
Wan 2.6 采用模块化架构,具有三条独立的生成路径。T2V、I2V 和 R2V 路径均针对其特定输入类型进行了独立优化。这种分离提供了更清晰的生产约束和更可预测的表现,有利于需要在大规模内容生产中获得一致、可重复结果的团队。尤其是 R2V 路径,代表了在多个镜头中保持角色一致性方面的重大进展。
功能对比:至关重要的能力
多模态输入处理
这是两款模型之间最显著的区别之一。
Seedance 2 支持全面的多模态输入,能够在一个生成请求中接受多达 12 种不同的资产。用户可以同时提供用于视觉风格的参考图、用于动作和镜头的视频剪辑、用于节奏的音轨以及用于叙事引导的详细文本提示。该模型使用自然语言 @ 提及系统来指定如何利用每个上传的资产。
这种多模态能力实现了前所未有的创作控制。例如,创作者可以通过视频剪辑参考特定电影的摄影,应用照片中的调色,同步音乐轨道的节奏,并通过文本引导叙事——所有这些都在一次生成中完成。这种水平的综合控制在以前的生成式视频中是无法想象的。
Wan 2.6 采取了更为结构化的方法,拥有三个专门的端点。T2V 路径处理纯文本驱动生成,增强了基于 LLM 的提示词扩充,可在镜头过渡中保留叙事语境;I2V 路径专注于为静态图像制作动画时的动作连贯性;R2V 路径则专门解决角色一致性问题,允许创作者在多个生成的视频片段中保持稳定的主体身份。
虽然 Wan 2.6 的方法在同时输入灵活性上不如 Seedance 2,但其专门的路径为特定生产场景提供了更清晰的指导和更可预测的输出。
视听同步
两款模型均随视频生成原生音频,消除了后期音频制作的需求——这相较于早期的 AI 视频模型是工作流上的重大改进。
Seedance 2 在对口型精度和情感化音频表现方面展示了非凡的实力。双分支架构并行处理音频和视频,实现了对话、面部表情和嘴部动作的帧精度同步。社区反馈经常强调“Seedance 时刻”,即视听同步达到近乎照片级的质量,特别是在特写对话场景和情感表演中。
该模型生成的对话、环境音效和实时音效能逐帧匹配视觉内容。这种整合方法产生的自然语音驱动动画具有电影感而非合成感,使其在叙事内容、角色驱动的故事以及任何需要可信的人机交互的应用中极具价值。
Wan 2.6 也提供了具有精确对口型能力的原生视听同步。该模型在生成层面集成了对口型和对话时机,产生适合专业应用的自然语音驱动动画。虽然 Wan 2.6 在该领域表现良好,但对比测试表明它在广告和结构化内容场景中更为出色,而 Seedance 2 则在极特写对话等场景中表现更佳。
动作控制与物理精度
逼真动作和物理模拟是将专业级 AI 视频与明显的人造内容区分开的关键。
Seedance 2 展示了强大的物理精确度,物体会遵循真实世界的规则下落、碰撞和互动。该模型能处理复杂的镜头语言,包括希区柯克变焦(dolly zoom)、移焦(rack focus)、追踪镜头、视角(POV)切换和顺滑的手持运动。动作序列(包括打斗、飞车、爆炸和坠落碎片)渲染出的物理效果和运动连贯性极具说服力。
社区对比指出,Seedance 在处理写实场景方面表现尤为优异,一项分析称其为“胜任的纪录片导演”,写实性是其传统优势。该模型在自然的肢体动作和表情方面表现卓越,尽管一些用户反映在复杂场景中偶尔会出现角色重复的情况。
Wan 2.6 相比前代 Wan 2.5 提供了增强的动作连贯性,尤其擅长维持多镜头序列中的叙事连续性。该模型的提示词处理经过专门改进,可在场景转换中保留语境,减少了在创建多场景序列时对提示词工程的需求。
角色与视觉一致性
在 AI 视频生成中,跨镜头和场景保持一致的角色外观是一项关键挑战。
Seedance 2 在面部、服装、文本、场景和视觉风格的一致性方面有了显著提升。模型在帧与镜头之间保持稳定的角色外观,解决了 AI 视频中常见的角色漂移、风格不一和细节丢失等问题。多模态参考系统允许创作者通过参考图锁定特定角色的外观,同时改变场景的其他方面。
Wan 2.6 通过其 R2V(参考转视频)路径专门解决了一致性挑战。这种专门模式专注于主体一致性,允许创作者在多个生成的视频片断中保持角色身份。R2V 路径代表了 Wan 2.6 相比前代最重要的改进之一,直接解决了曾阻碍 AI 视频工具在专业制作环境中广泛采用的核心痛点。
提示词遵循与指令服从
准确理解并执行复杂创作指令的能力决定了实现理想结果所需的受控迭代次数。
Seedance 2 强调详细的指令遵循,特别是对于需要同时处理多个主体、动作和镜头信号的场景。模型能精准理解并执行复杂提示词,其自然语言控制系统允许创作者直观地描述参考的使用方式。提示词越详细(包含特定镜头角度、时空节点和参考指令),输出就越精确。
Wan 2.6 提供了比 Wan 2.5 更强的指令遵循能力,其增强的提示词处理更好地保留了跨镜头过渡的叙事语境。基于 LLM 的提示词扩充系统经过优化,减少了多场景序列的提示词工程需求。这一改进使得 Wan 2.6 对于没有丰富 AI 提示词撰写经验的用户更加友好。
性能基准:真实世界测试结果
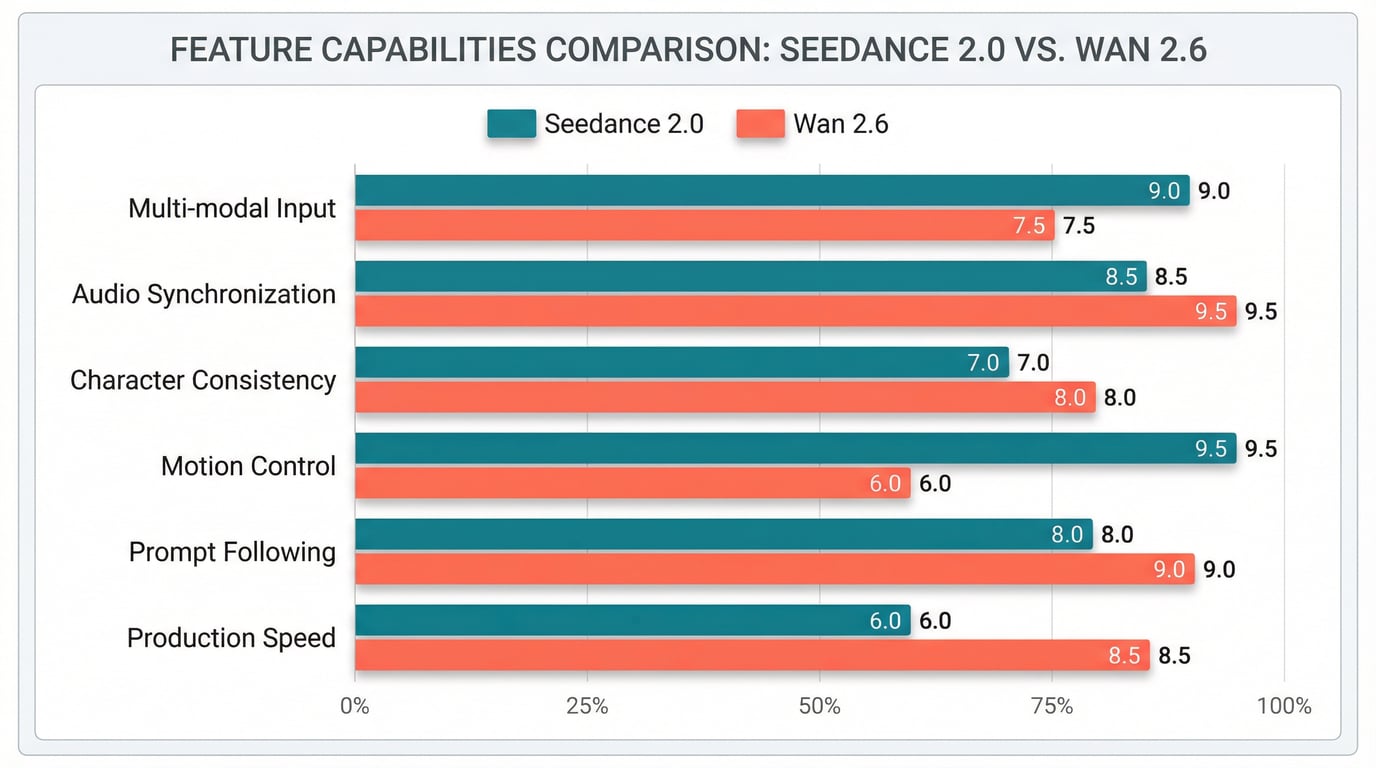
社区测试和基准对比提供了这两款模型在各种场景下表现的宝贵见解。
Artificial Analysis 排名
在 Artificial Analysis(一个通过公众投票而非内部指标对视频生成器进行排名的平台)上,Seedance 1.0 在文本转视频和图像转视频生成方面均获得了第一名,超过了 Veo 3、Kling 2.0、OpenAI 的 Sora、Runway Gen4 和 Wan 2.1。虽然这些排名早于 Wan 2.6 的发布,但它们确立了 Seedance 在更广泛 AI 视频领域的强势竞争力。
特定场景下的表现
在特定场景下的对比测试揭示了各自独特的优势:
人群场景与大规模动作:Seedance 在管理写实人群行为和大规模动作方面表现出色,尽管偶尔会增加轻微的镜头漂移(可通过微调提示词纠正)。Wan 2.6 在较小的人群场景中表现尚可,但在密集场景中会出现伪影。
动作与特效:对于爆炸或火焰等动态动作序列和视觉特效,Seedance 产生的烟雾模拟和时机非常强大,尽管光照偶尔会过亮。Wan 2.6 在结构化的动作序列中展示了能力,但在极端场景下可能表现出不稳定性。
角色动画:Seedance 擅长自然的肢体动作和面部表情,具有非常出色的对口型质量,特别是在对话繁重的内容中。Wan 2.6 提供适合广告和结构化内容的稳固角色动画,R2V 路径专门满足了角色一致性的需求。
生成速度
Seedance 2 据报道比前代 Seedance 1.5 快 30%,根据复杂程度和时长,生成通常在几分钟内完成。社区反馈将 Seedance 1.5 视为主要模型中的速度领先者,这表明 Seedance 2 维持了极具竞争力的生成时间。
Wan 2.6 实现了快速的生成速度,特别是通过优化后的平台访问时。根据视频长度和复杂度,生成通常需要 1-3 分钟。结构化路径的方法可能有助于在不同生成模式下提供可预测的处理时间。
实际应用:什么样的用例选择什么样的模型
选择最佳模型取决于具体的生产要求、内容类型和工作流约束。
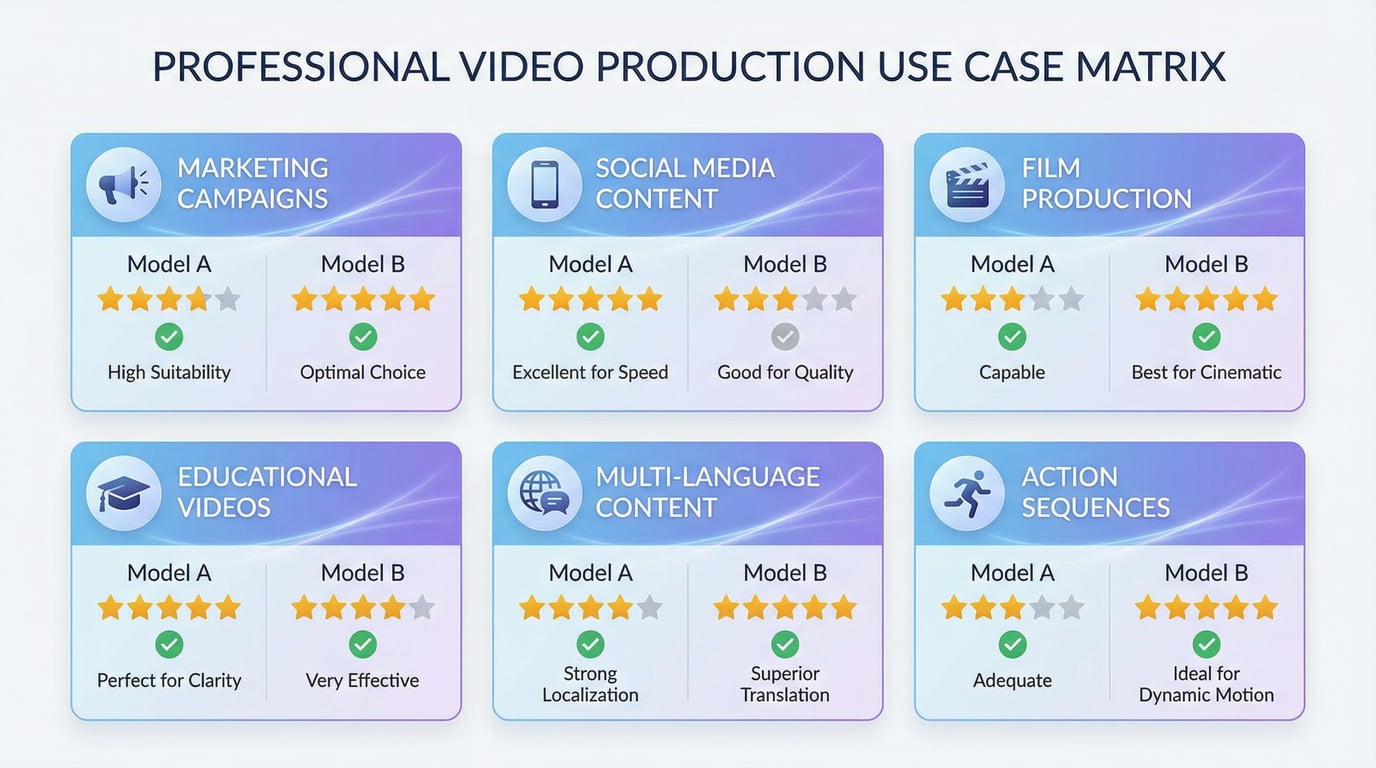
Seedance 2 的优势在于:
叙事与电影感内容:多模态参考系统和卓越的视听同步使得 Seedance 2 非常适合需要情感深度、角色驱动叙事和电影品质的故事讲述应用。制作分镜、概念验证序列或氛围场景的电影制作人可以从该模型将多种创意参考合成为连贯视觉叙事的能力中受益。
对话密集型内容:双分支架构卓越的对口型精度和微表情渲染,使 Seedance 2 成为包含人物对话、情感表演和近距离角色互动的首选。教育内容创作者、讲解视频制作人以及任何创建对话式内容的人都会发现该能力的巨大价值。
复杂多参考项目:当项目需要综合多种来源的灵感——例如匹配某一参考的摄影风格、另一参考的配色方案、某一音轨的节奏以及详细的叙事提示词时,Seedance 2 接受多达 12 个同时输入资产的能力提供了无与伦比的创意控制。
写实纪录片风格内容:社区测试一致认为写实性是 Seedance 的传统优势,这使其特别适合纪录片式内容、写实场景以及任何对真实感和自然动感要求极高的应用。
Wan 2.6 的优势在于:
结构化营销与广告:三条专门的生成路径提供了清晰的生产约束和可重复的工作流,非常适合需要产出一致品牌内容的营销团队。结构化方法确保了跨活动的可预测输出,使 Wan 2.6 成为可重复生产环境下的更稳妥选择。
角色一致性需求:R2V 路径专门解决了跨多个片段保持角色身份的挑战。创建吉祥物内容、具有常驻角色的剧集或任何需要在多段视频中保持一致角色外观的应用都将受益于这一专门能力。
多镜头叙事动态宣传:Wan 2.6 强大的多镜头叙事能力支持场景间的连贯故事讲述,适用于品牌宣传片、教育系列内容以及需要跨多个片段维持叙事连续性的结构化视频活动。
开发集成与 API 工作流:Wan 2.6 的开源特性和广泛的 API 集成选项使其对将视频生成集成到应用中的开发者、需要本地部署的平台以及需要针对特定用例定制模型行为的团队极具吸引力。
预算敏感型生产:Wan 2.6 的开源性质和极具竞争力的 API 定价,使其成为每段视频成本是重要考虑因素的高通量生产工作流的经济之选。
获取模型:平台可用性
两款模型均可通过多个平台获取,但可用性因地区和访问方式而异。
Seedance 2 目前已在中国境内上线,预计将于 2026 年第二季度全球推广。该模型可通过各种 API 供应商和集成了字节跳动视频生成能力的平台访问。对于寻求立即体验 Seedance 2 先进能力的创作者和企业,Seedance 2.0 提供了一个方便的入口。
Wan 2.6 得益于其开源特性和广泛的平台集成,拥有更广的可用性。该模型可通过多个 API 供应商、开发者平台和第三方集成获取。创作者可以通过 Wan 2.6 访问,该平台在一个统一界面中提供了对全部三条生成路径(T2V, I2V, R2V)的流线化访问。
SeaDanceAI 平台提供了对多种尖端视频和图像生成模型的访问,让创作者可以灵活地为每个特定项目选择最佳模型,而无需管理多个独立的集成。这一统一的访问点简化了跨不同内容类型和制作要求的团队工作流管理。
更广泛的竞争格局
虽然本次对比侧重于 Seedance 2 和 Wan 2.6,但了解它们相对于其他主要模型的地位也能提供有价值的背景。
快手的 Kling 3.0 提供原生 4K/60fps 以及内置的多镜头故事板功能,代表了目前最高的分辨率选项。然而,这伴随着极高的定价,对于 1080p 输出已足够的生产场景来说可能有些大材小用。
Google DeepMind 的 Veo 3.1 在封闭模型中拥有最全面的音频包,在单次生成中涵盖对话、拟音、环境音和音乐意识。Veo 3.1 还提供真正的 4K 输出,尽管其访问权限受限于 Google 的逐层滚动发布。
OpenAI 的 Sora 2 在物理精度和综合音频生成方面表现卓越,在许多维度上设定了质量上限。然而,其访问权限仍然受限,且商业用途的定价尚未公开。
在这种竞争格局中,Seedance 2 和 Wan 2.6 通过即时的实用可用性、生产级质量以及针对特定用例的清晰价值主张而脱颖而出。两者均不试图在每个维度都做到最强,而是各展所长,完美契合了不同的制作需求。
决策框架:选择您的模型
AI 视频生成市场在 2026 年已趋于成熟,不再是宣告单一“赢家”,而是需要将模型优势与特定生产需求相匹配。
在以下情况下选择 Seedance 2:
-
视听同步质量至关重要
-
项目需要综合多个创意参考
-
对话、情感和角色表演是内容的核心
-
电影质感和氛围叙事是首要任务
-
您需要最高质量的对口型和微表情
-
您的重点是写实的纪录片式内容
在以下情况下选择 Wan 2.6:
-
可重复、一致的生产工作流必不可少
-
需要在多个镜头中保持角色一致性
-
您正在制作结构化的营销或广告内容
-
开发集成和 API 灵活性是首选
-
预算约束倾向于开源选项
-
您的团队看重清晰的生产路径和可预测的输出
在以下情况下考虑两者并用:
-
您正制作发挥各自模型优势的多样化内容
-
您想针对同一创意简报测试不同的模型表现
-
您的制作量足以支撑维护多个工具集成
-
不同团队成员有不同的技能水平和工作流偏好
AI 视频生成的未来
从 Seedance 1.0 到 Seedance 2 以及从 Wan 2.5 到 Wan 2.6 的快速进步,展示了 AI 视频生成领域不断加速的创新节奏。目前正在形成几个将塑造下一代工具的趋势:
分辨率和帧率的提升持续将 4K 和 60fps 推向标准输出而非溢价功能。虽然目前的 1080p/24fps 已满足大多数需求,但轨迹已非常清晰。
更长的时长能力正在突破目前 15 秒的上限。由于计算要求和一致性维护,生成长篇内容依然具有挑战性,但随着每次模型迭代,增量改进正在不断涌现。
增强的控制界面正从文本提示和参考图演向更直观的创意指引系统。Seedance 2 的自然语言 @ 提及系统代表了一种尝试;未来迭代可能会整合更复杂的控制机制。
生产工作流集成正变得愈发重要,这些工具正从实验性新奇物转变为必不可少的生产基础设施。API 可靠性、批量处理能力以及与现有创意软件的集成,将区分出专业级工具与消费级应用。
结论:生产级 AI 视频已经到来
Seedance 2 与 Wan 2.6 的对比揭示了当前 AI 视频生成状态的一个基本事实:我们已经跨越了“AI 是否能创建专业视频”的问题,转向了“哪款专门工具能最好地服务于特定创意需求”这一更为细微的问题。
Seedance 2 代表了多模态创意控制和电影感品质的前沿,特别是在视听同步、情感表演和复杂参考合成方面表现卓越。其统一架构和单次处理多达 12 个同时输入资产的能力,为叙事和角色驱动的内容提供了前所未有的创作灵活性。
Wan 2.6 通过针对特定用例优化的专门生成路径,提供了结构化、可重复的生产工作流。其参考转视频能力解决了关键的角色一致性需求,而其开源性质和广泛的 API 集成选项使其对开发者和预算敏感型制作团队极具吸引力。
没有哪款模型是普遍优越的;每款模型在对不同生产场景具有重要意义的维度上都各有所长。成熟的做法是理解这些优势,并为每个特定项目匹配合适的工具。
对于在这一领域导航的创作者、营销人员和制作团队,实际建议非常清晰:在您实际生产线中具有代表性的内容上对两款模型进行测试。输出质量、工作流效率和创意控制上的差异很快就会显现,让您能基于真实结果而非规格参数做出明智的决策。
AI 视频生成的革命已经不再只是个预言,它就在这里。像 Seedance 2 和 Wan 2.6 这样的工具已经在为全球的商业广告、社交媒体活动、教育材料和创意项目产出内容。问题不再是是否采用这些工具,而是如何将它们最有效地集成到您的创作流中。
通过像 Seedance 2.0 和 Wan 2.6 这样的统一平台获取这两款模型,亲身体验它们的能力,探索哪款能最好地服务于您的独特创意愿景。


