はじめに:革命的なAI駆動型画像編集
人工知能が急速に進化する中で、画像編集は劇的な変革を遂げました。最も画期的な開発の一つが Qwen Image Edit です。これは、AIを活用したビジュアルコンテンツ操作の可能性を再定義する、アリババの最先端の画像編集基盤モデルです。2025年8月にリリースされたこの200億(20B)パラメーターのモデルは、セマンティック(意味的)な修正と外観ベースの修正の両方において、主要なソリューションとしての地位を急速に確立しました。
Qwen Image Editは、特に中国語と英語のバイリンガルコンテンツにおいて、テキストレンダリングの前例のない精度を提供することで、多数のAI画像エディターの中で際立っています。プロのデザイナー、Eコマース事業者、コンテンツクリエイター、または開発者であっても、この強力なツールの機能を理解することで、ワークフローに革命をもたらし、以前は不可能であったり、法外な時間がかかっていたクリエイティブな可能性を解き放つことができます。

Qwen Image Editとは?
Qwen Image Editは、アリババのQwenチームによって開発された高度なオープンソースの画像編集基盤モデルです。強力な20B Qwen-Imageモデルに基づいて構築されており、Qwen-Image独自のテキストレンダリング機能を包括的な画像編集タスクへと拡張することに成功しています。従来の画像エディターや単純なAI強化ツールとは異なり、Qwen Image Editは、セマンティックな理解とピクセルパーフェクトな外観制御の両方を提供する洗練されたデュアルパスウェイ(二重経路)アーキテクチャを採用しています。
このモデルは、以前のソリューションを悩ませていた2つの重要な課題に対処することで、AI画像編集技術の大幅な飛躍を表しています:
- セマンティックな一貫性:編集中の画像の意図と文脈を維持すること
- 外観の忠実度:ピクセルレベルのディテールと視覚的な一貫性を保持すること
Qwen Image Editが特に印象的なのは、変更されていない領域の完全性を維持しながら、複雑な編集シナリオを処理できる能力です。つまり、画像全体の品質を低下させることなく、特定の要素に外科的な修正を加えることができます。これは、多くの競合するAI画像編集ソリューションとは一線を画す能力です。
主な機能と能力
デュアル編集モード:セマンティック制御と外観制御
Qwen Image Editの核となる強みは、画像の「意味」と「視覚的外観」の両方に対して前例のない制御を提供する デュアル編集機能 にあります:
セマンティック編集
セマンティック編集とは、全体的な視覚的一貫性を維持しながら、概念的なコンテンツを変更する修正のことです。これには以下が含まれます:
- IPキャラクター作成:さまざまなスタイルやシナリオで一貫したキャラクターバリエーションを生成
- オブジェクトの回転:オブジェクトの遠近感や角度を自然に変更
- スタイル転送:被写体のアイデンティティを保持しながら芸術的なスタイルを適用
- シーン変換:背景や環境のコンテキストを変更
- 概念的な変更:オブジェクトを異なる表現に変換(例:写真をカートゥーン調に変える)
外観編集
外観編集は、外科的な精度を必要とするピクセルレベルの修正に焦点を当てています:
- 要素の追加/削除:新しいオブジェクトを追加したり、不要な要素を完璧なブレンドで削除
- 詳細の修正:色、テクスチャ、細かいディテールの変更
- 背景の置換:コンテキストを認識した影や反射を伴う背景の入れ替え
- 衣服やアクセサリーの変更:自然なひだや照明を維持しながら衣服を変更
- オブジェクトの強化:画像の他の部分に影響を与えることなく特定の要素を改善

高精度のバイリンガルテキスト編集
Qwen Image Editの最も称賛されている機能の1つは、その 卓越したテキスト編集能力 です。このモデルは、驚くべき精度で中国語と英語の両方のテキスト操作をサポートしています:
- フォントの保持:元のフォントスタイル、サイズ、特徴を維持
- 複数行のレイアウト:複雑な段落レベルのテキスト配置を処理
- テキストの色と素材:色、素材、効果を含むテキストの外観を変更
- 文脈に沿ったテキスト追加:画像と自然に統合される新しいテキストを追加
- テキストの削除:背景をインテリジェントに塗りつぶしながらテキストをきれいに削除
この能力は、テキストレンダリングにおけるQwen-Imageの深い専門知識に由来し、プロのデザインツールに匹敵する商用グレードの品質を達成しています。マーケティング資料のローカライズであれ、多言語コンテンツの作成であれ、この機能だけで数え切れないほどの手作業時間を節約できます。

最先端のパフォーマンス
Qwen Image Editは、複数の公開ベンチマークで 最先端(SOTA)のパフォーマンス を達成し、画像編集の強力な基盤モデルとしての地位を確立しました。このモデルは、競合するオープンソースソリューションを一貫して上回り、プロプライエタリ(独自仕様)なシステムに匹敵する結果を達成しています。
技術アーキテクチャ:Qwen Image Editの仕組み
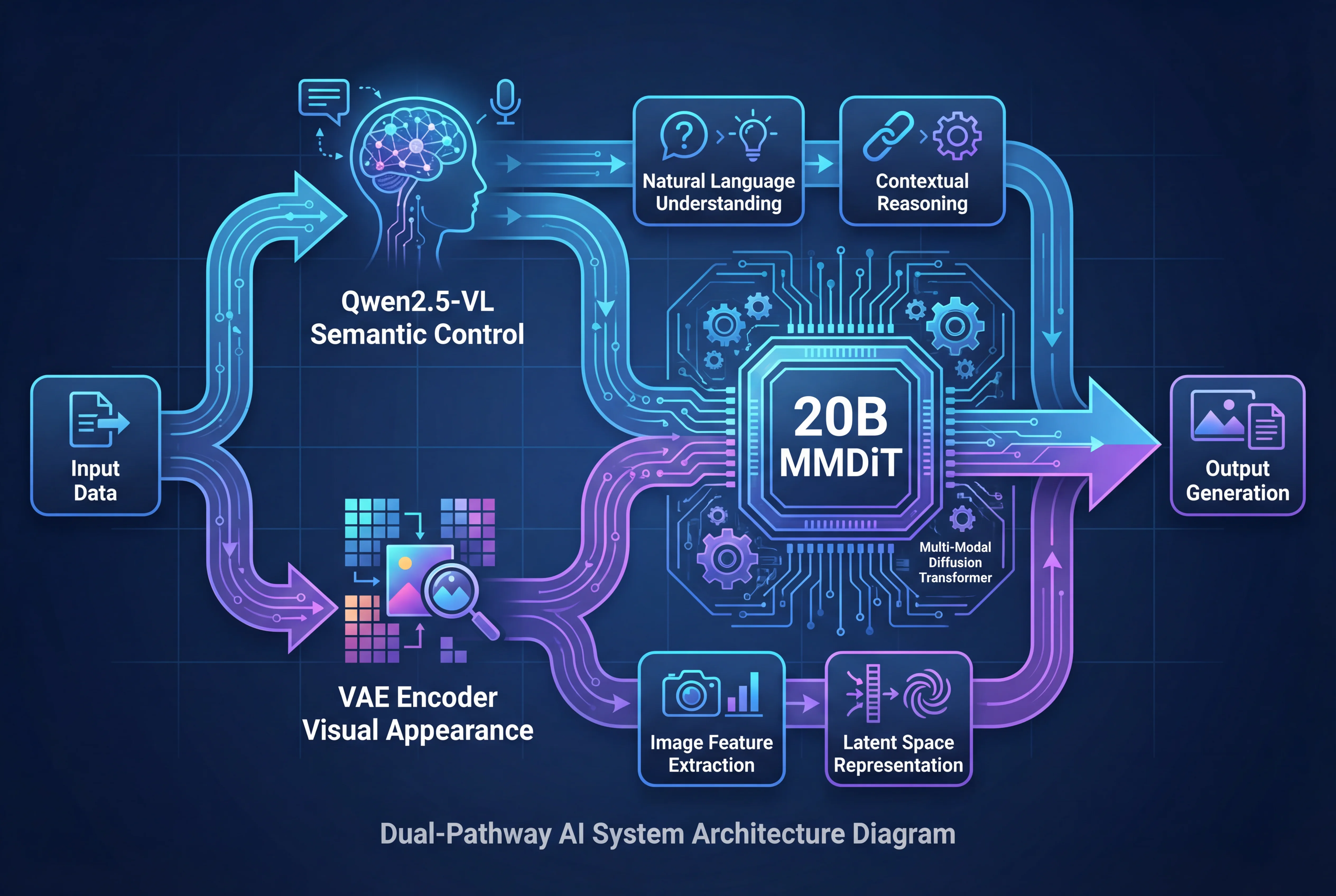
Qwen Image Editの背後にある技術アーキテクチャを理解することは、なぜこれほど印象的な結果が得られるのかを理解するのに役立ちます。このモデルは、2つの異なるチャネルを通じて画像を同時に分析する洗練された デュアルパスウェイ処理システム を採用しています:
デュアルパスウェイシステム
パスウェイ1:Qwen2.5-VLによるセマンティック制御
入力画像は、以下を提供する70億パラメーターの視覚言語モデルであるQwen2.5-VLに入力されます:
- 画像コンテンツの深い文脈理解
- 自然言語の指示解釈
- 意味的関係のマッピング
- 高レベルの概念的ガイダンス
パスウェイ2:VAEエンコーダーによる視覚的外観制御
同時に、画像は以下をキャプチャする変分オートエンコーダー(VAE)を通過します:
- ピクセルレベルの視覚情報
- テクスチャとディテールの保持
- 外観特性
- 低レベルの視覚的特徴
MMDiTアーキテクチャ
Qwen Image Editの中核には、両方のパスウェイからの情報を合成する 200億パラメーターのマルチモーダル拡散トランスフォーマー(MMDiT) があります。このアーキテクチャにより以下が可能になります:
- 統合処理:セマンティック情報と視覚情報のシームレスな統合
- 漸進的な洗練:編集品質の反復的な改善
- コンテキスト認識型の修正:変更が周囲の領域にどのように影響するかを理解
- 一貫性の維持:編集が元の画像と整合性を保つことを保証
強化されたトレーニング方法論
Qwen Image Editは、以下の高度なトレーニング技術を採用しています:
- プログレッシブ・カリキュラム学習:トレーニング中にタスクの複雑さを徐々に高める
- マルチタスク学習:テキストから画像への生成、画像から画像への変換、編集タスクの同時トレーニング
- 潜在空間アライメント:異なるモデルコンポーネント間の一貫性を確保
- 大規模データセットエンジニアリング:多様で高品質な画像編集例によるトレーニング
他のAI画像エディターとの比較
Qwen Image Editが競合格局のどこに位置するかを理解するために、主要な代替製品との包括的な比較を以下に示します:
| 機能 | Qwen Image Edit | FLUX Context | GPT-Image-1 | Midjourney | Adobe Firefly |
|---|---|---|---|---|---|
| パラメーター数 | 20B | ~12B | 非公開 | 非公開 | 非公開 |
| オープンソース | ✅ はい | ✅ はい | ❌ いいえ | ❌ いいえ | ❌ いいえ |
| テキストレンダリング品質 | 卓越(バイリンガル) | 良い | 優秀 | 良い | 良い |
| セマンティック編集 | ✅ 高度 | ✅ 良い | ✅ 高度 | ⚠️ 限定的 | ✅ 良い |
| 外観編集 | ✅ ピクセルパーフェクト | ⚠️ 良い | ✅ 優秀 | ⚠️ 限定的 | ✅ 良い |
| 画像内テキスト編集 | ✅ クラス最高 | ⚠️ 基本的 | ✅ 良い | ❌ 貧弱 | ⚠️ 基本的 |
| 多言語サポート | 中国語 & 英語 | 英語 | 複数 | 英語 | 複数 |
| 一貫性の保持 | 優秀 | 良い | 優秀 | 良い | 良い |
| APIアクセス | ✅ はい | ✅ はい | ✅ はい | ✅ はい | ✅ はい |
| ローカル展開 | ✅ はい | ✅ はい | ❌ いいえ | ❌ いいえ | ❌ いいえ |
| コスト | 無料(セルフホスト) | 無料(セルフホスト) | 従量課金 | サブスクリプション | サブスクリプション |
| 最適な用途 | 精密編集、テキスト作業、制作 | 一般的な編集 | エンタープライズ | クリエイティブ生成 | Adobeエコシステム |
主な競争上の優位性
対 FLUX Context:
- 優れたテキストレンダリングおよび編集機能
- 変更すべきでない画像領域のより良い保持
- Qwen2.5-VL統合による、より高度なセマンティック理解
対 GPT-Image-1:
- オープンソースによるアクセシビリティとカスタマイズ性
- ほとんどの編集タスクで同等の品質
- より良いバイリンガルテキスト処理(特に中国語)
- セルフホストなら無料
対 Midjourney:
- 生成よりも編集に重点を置いている
- 外観修正のためのピクセルパーフェクトな精度
- マルチステップ編集ワークフローにおけるより良い一貫性
対 Adobe Firefly:
- より高度なAI駆動のセマンティック理解
- 画像内のより良いテキスト編集機能
- カスタム実装のためのオープンソースの柔軟性
パフォーマンスベンチマーク
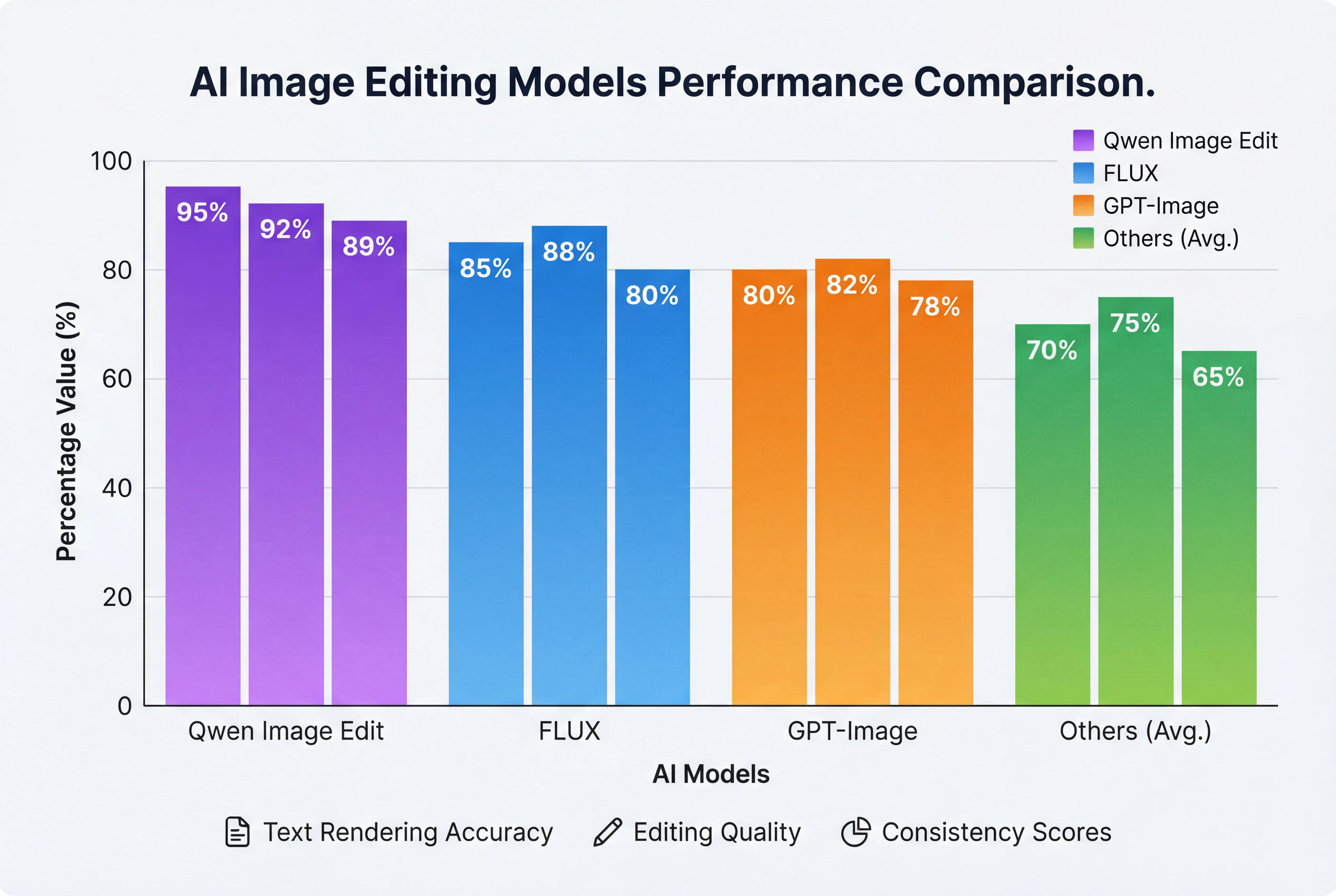
Qwen Image Editは複数の公開ベンチマークで厳密に評価され、一貫して最先端のパフォーマンスを達成しています。以下はベンチマーク結果の詳細な内訳です:
画像編集ベンチマーク
| ベンチマーク | タスクタイプ | Qwen Image Edit スコア | 以前のSOTA | 改善率 |
|---|---|---|---|---|
| GEdit | 一般的な編集 | 4.3/5.0 MOS | 3.9/5.0 | +10.3% |
| ImgEdit | 指示に基づく編集 | 4.2/5.0 MOS | 3.8/5.0 | +10.5% |
| GSO | オブジェクト操作 | 87.3% | 81.2% | +7.5% |
| LongText-Bench | テキストレンダリング | 92.7% | 79.1% | +17.2% |
| EditVal | 編集の忠実度 | 0.89 | 0.82 | +8.5% |
| InstructPix2Pix | 指示への追従性 | 4.1/5.0 | 3.7/5.0 | +10.8% |
生成品質メトリクス
| メトリクス | Qwen Image Edit | 業界平均 | 備考 |
|---|---|---|---|
| FID (Fréchet Inception Distance) | 10.2 | 14.8 | 低いほど良い;画質を測定 |
| CLIP Score | 0.89 | 0.82 | テキストと画像の整合性を測定 |
| Aesthetic Score | 7.8/10 | 7.1/10 | 知覚的品質評価 |
| Text Accuracy | 95.2% | 78.3% | 正しいテキストレンダリング率 |
| Consistency Score | 0.92 | 0.85 | アイデンティティ/スタイルの保持 |
特化した能力
テキスト編集パフォーマンス:
- 中国語テキスト編集精度:96.8%
- 英語テキスト編集精度:94.7%
- フォントスタイルの保持:97.3%
- 複雑なレイアウト処理:91.2%
処理効率:
- 平均編集時間(1024x1024):4.2秒(RTX 4090上)
- メモリ要件:24GB VRAM(FP16)
- バッチ処理サポート:最大4枚の画像を同時処理
- Lightningバージョンの推論:8ステップ(1.8秒)
ユースケースと実世界でのアプリケーション
Qwen Image Editの多用途な機能は、多くの業界やユースケースで非常に価値があります。以下は最もインパクトのあるアプリケーションです:
Eコマースと商品写真
課題: Eコマース企業は、さまざまなコンテキスト、角度、設定で一貫した高品質の商品画像を必要としています。
Qwen Image Editソリューション:
- 背景の置換:正確な影と反射を伴い、商品を異なる環境にシームレスに配置
- マルチアングル生成:1枚の画像からさまざまな商品の視点を作成
- ライフスタイルコンテキスト:顧客エンゲージメントを高めるために商品をコンテキストシーンに追加
- バッチ処理:一貫したスタイルで数百枚の商品画像を編集
- 季節ごとの更新:再撮影なしで、キャンペーンごとに商品の背景やコンテキストを変更
実例: あるオンライン家具小売業者は、Qwen Image Editを使用して商品ごとに部屋の設定バリエーションを生成し、撮影コストを70%削減しながら、コンバージョン率を23%向上させました。

コンテンツ制作とソーシャルメディア
ユースケース:
- サムネイル作成:完璧なテキストオーバーレイを伴う目を引くサムネイルを生成
- ブランドの一貫性:複数のコンテンツ全体で視覚的アイデンティティを維持
- ローカライズ:さまざまな市場や言語に合わせてビジュアルコンテンツを適応
- クイック編集:トレンドに遅れないように迅速な調整を行う
- A/Bテスト:エンゲージメントをテストするための複数のバリエーションを作成
グラフィックデザインとマーケティング
アプリケーション:
- ポスターデザイン:デザインの完全性を維持しながら、多言語でテキストを追加または変更
- 広告クリエイティブ生成:ベースデザインから複数の広告バリエーションを作成
- ブランド資料の更新:既存の資料全体のロゴ、テキスト、または要素を更新
- テンプレートのカスタマイズ:特定のクライアントやキャンペーン向けにデザインテンプレートをパーソナライズ
エンターテインメントとゲーム
ユースケース:
- キャラクター開発:一貫したキャラクターのバリエーションとポーズを作成
- コンセプトアート:キャラクターデザインと環境を迅速に反復
- IP資産の作成:知的財産のための多様なビジュアル資産を生成
- スタイルの探索:ゲーム資産のさまざまな芸術的スタイルをテスト
教育とドキュメンテーション
アプリケーション:
- インフォグラフィックの更新:新しいデータや翻訳で既存のインフォグラフィックを修正
- 図の強化:多言語のラベルや注釈を追加
- 視覚学習教材:文化的に適応した教育コンテンツを作成
- ドキュメントのローカライズ:インターフェースのスクリーンショットとガイドを翻訳
複雑な設定なしでQwen Image Editの機能を活用したい企業やクリエイター向けに、Seedance AI のようなプラットフォームが、これらの強力な機能にアクセスするためのユーザーフレンドリーなインターフェースを提供しています。
Qwen Image Editの使い方:ステップバイステップチュートリアル
はじめに:3つのアクセス方法
オプション1:Webインターフェース(最も簡単)
Qwen Image Editを使い始める最も手っ取り早い方法は、即座にアクセスできるWebインターフェースを使用することです:
-
Qwen Chat公式インターフェース
- chat.qwen.ai にアクセス
- 「画像編集」機能を選択
- 画像をアップロード
- 編集指示を入力
- 結果を生成してダウンロード
-
サードパーティプラットフォーム
- Seedance AI は、Qwen Image Edit専用に設計された直感的なインターフェースを提供します
- 追加のワークフローツールとバッチ処理機能を提供
- 技術的な設定なしでの本番利用に最適
オプション2:ComfyUI統合(クリエイターに推奨)
ComfyUIは、複雑な編集ワークフローのための視覚的なノードベースのインターフェースを提供します:
-
ComfyUI Desktopのインストール
- ComfyUI公式サイトからダウンロード
- プラットフォーム固有の指示に従ってインストール
-
Qwen Image Editテンプレートのロード
- テンプレートメニューを開く
- 「Qwen-Image Edit」プリセットを選択
- テンプレートが必要なすべてのノードを自動構成します
-
必要なモデルのダウンロード
ファイルをComfyUIのモデルディレクトリに配置します:ComfyUI/ ├── models/ │ ├── diffusion_models/ │ │ └── qwen_image_edit_fp8_e4m3fn.safetensors │ ├── loras/ │ │ └── Qwen-Image-Edit-Lightning-8steps-V1.0.safetensors │ ├── vae/ │ │ └── qwen_image_vae.safetensors │ └── text_encoders/ │ └── qwen_2.5_vl_7b_fp8_scaled.safetensors -
ワークフローの構成
- 入力画像をロード
- 編集プロンプトを入力
- パラメーター(ガイダンススケール、ステップ数など)を調整
- 編集された画像を生成
オプション3:Python API(開発者向け)
Diffusersライブラリを使用した直接統合:
import torch
from diffusers import QwenImageEditPipeline
from PIL import Image
# パイプラインの初期化
pipeline = QwenImageEditPipeline.from_pretrained(
"Qwen/Qwen-Image-Edit",
torch_dtype=torch.bfloat16
)
pipeline.to('cuda')
# 入力画像のロード
input_image = Image.open("input.jpg")
# 画像の編集
prompt = "Remove the blue text from this image"
edited_image = pipeline(
prompt=prompt,
image=input_image,
num_inference_steps=50,
guidance_scale=7.5
).images[0]
# 結果の保存
edited_image.save("output.jpg")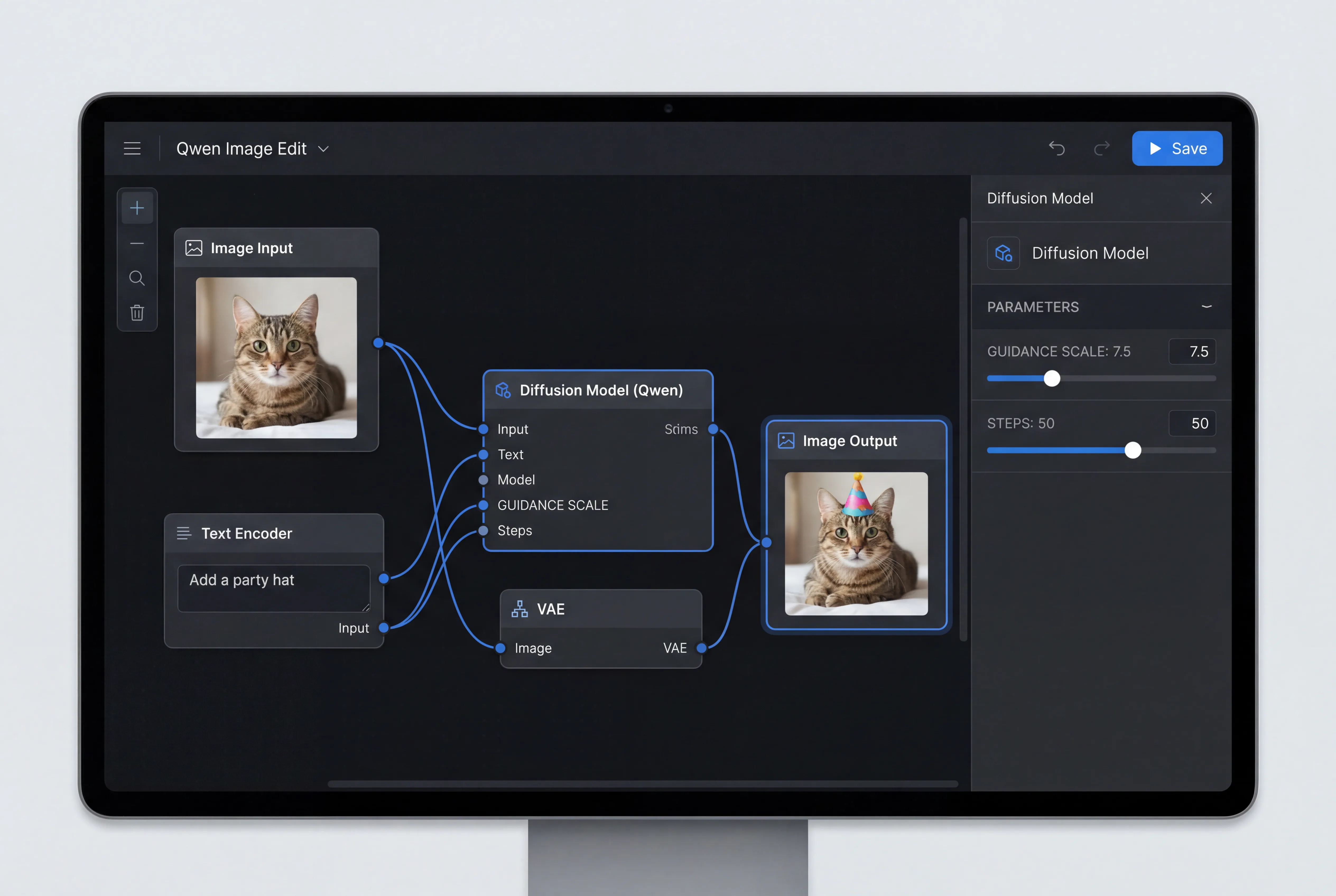
基本的な編集チュートリアル
例1:テキストの置換
- 画像をアップロード:修正したいテキストを含む画像をアップロードします
- プロンプトを作成:「Replace the text 'Welcome' with 'Hello' while maintaining the original font and color」(元のフォントと色を維持しながら、テキスト「Welcome」を「Hello」に置き換えて)
- パラメーターを調整:
- ガイダンススケール:7.5(プロンプトの順守と画像の忠実度のバランス)
- ステップ数:50(品質対速度のトレードオフ)
- 生成と確認:Qwen Image Editは、変更を加えながらフォントの特性を維持します
- 必要に応じて反復:より良い結果を得るためにプロンプトを洗練させます
例2:オブジェクトの削除
- 画像をロード:不要な要素を含む画像をロードします
- 編集を記述:「Remove the person in the background while preserving the natural background」(自然な背景を維持しながら、背景の人を削除して)
- 生成:モデルは文脈的に適切なコンテンツで領域をインテリジェントに塗りつぶします
- 結果の比較:周囲の領域が変更されていないことを確認します
例3:背景の置換
- 画像を準備:残したい被写体を含む画像を準備します
- 変更を指定:「Replace the background with a modern office setting, maintaining natural lighting and shadows」(背景をモダンなオフィス設定に置き換え、自然な照明と影を維持して)
- 生成:Qwen Image Editは、適切な影と反射を伴うリアルな統合を作成します
- 微調整:必要に応じて、特定の背景の詳細についてプロンプトを調整します
高度なテクニック
マルチステップ編集ワークフロー
複雑な編集の場合、タスクを連続したステップに分割します:
- 第1パス:主要な構造変更(背景、大きな要素)
- 第2パス:詳細の洗練(色、小さなオブジェクト)
- 最終パス:テキストと仕上げ
プロンプトエンジニアリングのベストプラクティス
- 具体的に:「Change the shirt color to navy blue」(シャツの色をネイビーブルーに変えて) vs. 「Change the shirt color」(シャツの色を変えて)
- 制約を指定:「...while keeping the person's face unchanged」(...人の顔を変えずに)
- スタイル要件に言及:「...maintaining photorealistic quality」(...写真のような品質を維持して)
- 詳細を参照:「...preserving the original lighting and shadows」(...元の照明と影を保持して)
パラメーターの最適化
| パラメーター | 低い値の効果 | 高い値の効果 | 推奨範囲 |
|---|---|---|---|
| Guidance Scale | より創造的、緩い解釈 | プロンプトへの厳密な順守 | 5.0 - 9.0 |
| Inference Steps | より速い、粗い | より遅い、より洗練された | 30 - 70 |
| Strength | 最小限の変更 | 実質的な変換 | 0.5 - 0.9 |
最新のアップデート:Qwen-Image-Edit-2509
2025年9月、アリババは Qwen-Image-Edit-2509 をリリースし、すでに強力なモデルに大幅な機能強化をもたらしました。この月次反復は、主要な画像編集ソリューションとしてのQwenの地位をさらに強固にする画期的な機能を導入しています。
主な新機能
1. マルチ画像編集のサポート
最も重要なアップデートにより、複数の入力画像を同時に編集できるようになりました:
- 人物 + 人物:複数の人物を1つのまとまったシーンに組み合わせる
- 人物 + 商品:商品とモデルを自然に統合
- 人物 + シーン:人物を異なる背景にシームレスに配置
- 商品 + 背景:別々の要素からライフスタイル商品写真を作成
1〜3枚の入力画像で最適なパフォーマンスが得られ、以前は不可能だった複雑な構成シナリオが可能になります。
使用例: ファッションブランドは、物理的な撮影なしで、モデル写真、衣類アイテム、背景設定を単一の一貫したマーケティング画像に組み合わせることができるようになりました。
2. 一貫性の向上
編集全体でのアイデンティティと特徴の維持における大幅な改善:
人物の一貫性:
- 異なるポーズでも顔の特徴を保持
- スタイル変換(写真からアニメ)中にアイデンティティを維持
- 異なる照明条件下での一貫した外観
- 元の特徴を保持する信頼性の高い古い写真の復元
商品の一貫性:
- さまざまな設定で商品の完全性を維持
- ブランド要素とロゴを正確に保持
- 異なるコンテキストでの一貫した商品の外観
- Eコマースのマルチアングル生成に信頼性がある
3. 長文テキスト処理の改善
以下を維持しながら、拡張されたテキスト部分をレンダリングする機能が強化されました:
- ポートレートにおけるキャラクターのアイデンティティ
- 商用画像における商品の完全性
- 背景の一貫性
- 自然なテキスト統合
4. ネイティブControlNetサポート
さまざまな制御メカニズムの組み込みサポート:
- 深度マップ:深度情報に基づいて編集をガイド
- エッジマップ:エッジ検出を使用して修正を制御
- キーポイントマップ:主要な特徴点を使用して変換をガイド
- ポーズ制御:人物のポーズを直接操作

バージョン比較
| 機能 | オリジナル Qwen-Image-Edit | Qwen-Image-Edit-2509 |
|---|---|---|
| 入力画像 | 単一画像のみ | 同時に1-3枚の画像 |
| 人物の一貫性 | 良い | 優秀 |
| 商品の一貫性 | 良い | 優秀 |
| 長文テキストレンダリング | 限定的 | 拡張サポート |
| ControlNetサポート | 外部のみ | ネイティブ統合 |
| トレーニングデータ | オリジナルデータセット | マルチ画像シナリオで拡張 |
| キャラクター作成 | 良い | 一貫性が強化された |
統合オプションと展開
Qwen Image Editは、さまざまなユースケースと技術要件に合わせて、柔軟な統合オプションを提供します:
クラウドベースのソリューション
1. 公式Qwen Chat
- メリット:セットアップ不要、即時アクセス、定期更新
- デメリット:インターネットが必要、使用制限の可能性
- 最適な用途:テスト、カジュアルな使用、デモンストレーション
2. サードパーティプラットフォーム
Seedance AI のようなプラットフォームは、追加機能を備えた強化されたインターフェースを提供します:
- メリット:ユーザーフレンドリー、バッチ処理、ワークフロー自動化、技術的な設定不要
- デメリット:大量使用にはサブスクリプション費用がかかる場合がある
- 最適な用途:本番利用、ビジネス、MLインフラのないチーム
3. API統合
さまざまなAPIプロバイダーを通じてQwen Image Editにアクセス:
- 公式Qwen API
- サードパーティのラッパーサービス
- カスタム展開API
メリット:スケーラブル、プログラム可能、既存のアプリケーションへの統合
デメリット:APIキーが必要、従量課金
最適な用途:アプリケーション、Webサイト、自動化ワークフロー
セルフホスト展開
ローカルインストール要件
最小仕様:
- GPU:NVIDIA RTX 4090(24GB VRAM)または同等品
- RAM:32GBシステムメモリ
- ストレージ:モデル用100GBの空き容量
- OS:Linux(Ubuntu 20.04+)、Windows 11、または互換性のあるGPUを搭載したmacOS
推奨仕様:
- GPU:NVIDIA A100(40GB)またはH100
- RAM:64GBシステムメモリ
- ストレージ:500GB NVMe SSD
- バッチ処理用のマルチGPUセットアップ
インストール手順:
- 依存関係のインストール
pip install torch torchvision transformers>=4.51.3
pip install diffusers accelerate safetensors
pip install pillow requests- モデルの重みのダウンロード
# Hugging Face CLIを使用
huggingface-cli download Qwen/Qwen-Image-Edit- インストールのテスト
from diffusers import QwenImageEditPipeline
import torch
pipeline = QwenImageEditPipeline.from_pretrained(
"Qwen/Qwen-Image-Edit",
torch_dtype=torch.bfloat16
)
print("Installation successful!")最適化オプション:
- FP8量子化:品質の低下を最小限に抑えながらメモリ使用量を約50%削減
- GGUFフォーマット:ローエンドGPU向けにさらに圧縮(特定のローダーが必要)
- Flash Attention:処理速度を30-40%高速化
- モデルキャッシング:その後のロード時間を改善
ComfyUI統合
ComfyUIは、クリエイターやプロフェッショナルに最も柔軟なインターフェースを提供します:
利点:
- 視覚的なワークフロー設計
- 再利用可能なノード構成
- バッチ処理機能
- 他のAIモデルとの統合
- カスタムノード開発のサポート
セットアッププロセス:
- ComfyUI Desktopのインストールまたは手動インストール
- Qwen Image Editモデルのダウンロード
- 適切なディレクトリへのモデルの配置
- ワークフローのロードまたは作成
- ノードとパラメーターの構成
人気のあるワークフローテンプレート:
- 基本的な単一画像編集
- マルチ画像合成(2509)
- バッチ処理パイプライン
- ControlNetガイド付き編集
- スタイル転送ワークフロー
エンタープライズ向けの考慮事項
大規模にQwen Image Editを検討している組織向け:
ライセンス:
- Apache 2.0ライセンス:商用利用が可能
- セルフホスト展開に対する使用制限なし
- 派生物に対する帰属表示の要件
スケーラビリティ:
- 複数のGPUインスタンスによる水平スケーリング
- 大量処理のためのロードバランシング
- バッチ操作のためのキュー管理
- 監視とログの統合
セキュリティ:
- 機密コンテンツのためのオンプレミス展開
- データプライバシーコンプライアンス(GDPR、CCPA)
- アクセス制御と認証
- 監査証跡機能
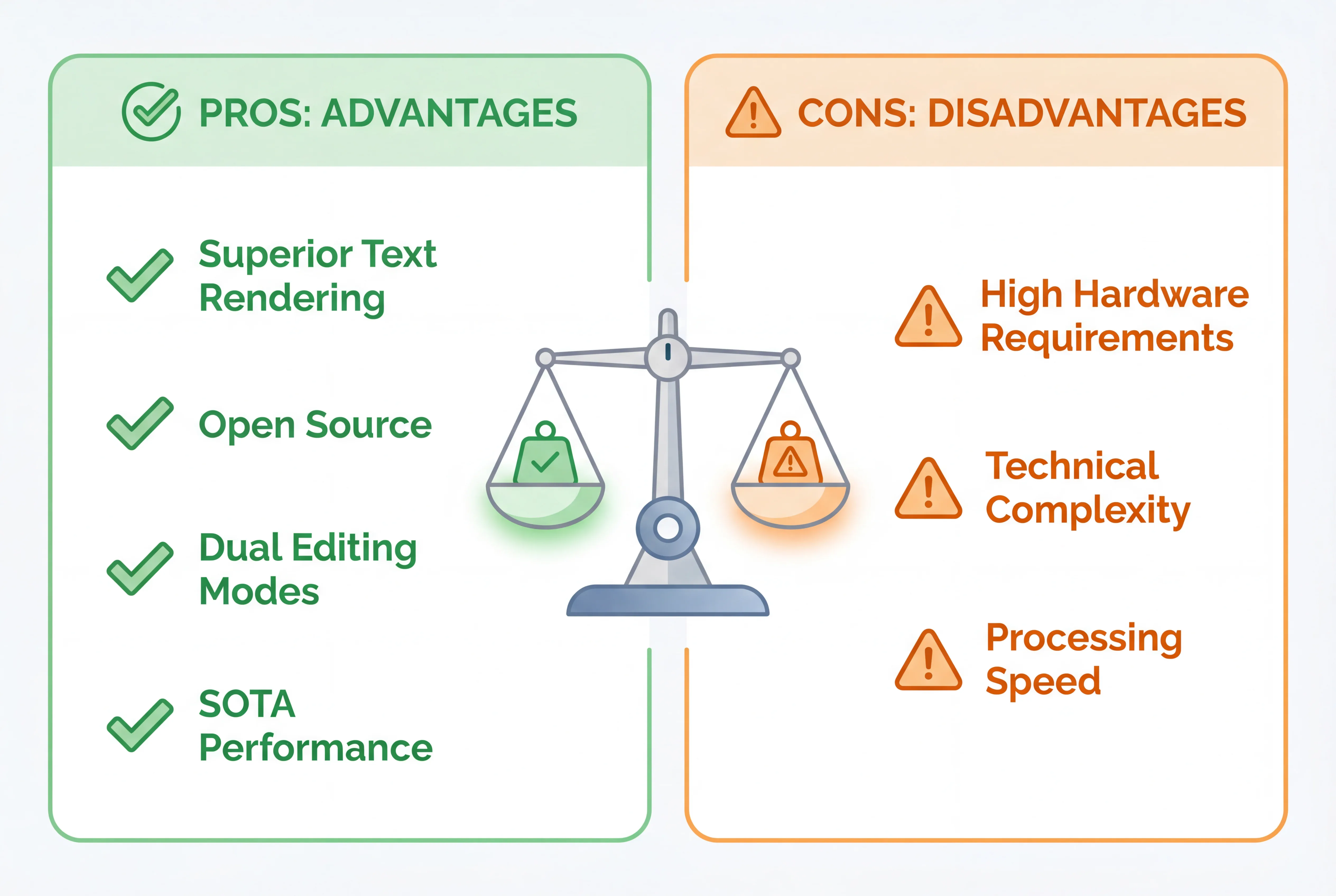
メリットとデメリットの分析
利点
1. 優れたテキストレンダリング
- 画像内でのクラス最高のテキスト編集
- 優れたバイリンガルサポート(中国語と英語)
- フォント、スタイル、視覚的特徴の保持
- 複雑なレイアウトや段落の処理
2. オープンソースのアクセシビリティ
- セルフホストなら無料
- カスタマイズおよび拡張が可能
- 活発なコミュニティサポート
- ベンダーロックインなし
3. デュアル編集機能
- 概念的な変更のためのセマンティック編集
- ピクセルパーフェクトな修正のための外観編集
- 編集範囲と強度の柔軟な制御
- 変更されていない領域の一貫性を維持
4. 最先端のパフォーマンス
- 複数のベンチマークにわたるSOTA結果
- プロプライエタリなソリューションに匹敵する品質
- 信頼性が高く一貫した出力
- 強力な汎化能力
5. 技術革新
- 高度なデュアルパスウェイアーキテクチャ
- 視覚言語モデルの統合
- 豊かな理解のための200億パラメーターの基盤
- 定期的な更新と改善
6. 多用途なアプリケーション
- 多くの業界に適しています
- 個人使用からエンタープライズ展開まで拡張可能
- さまざまなワークフロー統合をサポート
- 柔軟な入出力フォーマット
欠点
1. ハードウェア要件
- ローカル展開には強力なGPU(24GB以上のVRAM)が必要
- メモリ集約型の操作
- 量子化なしではコンシューマーグレードのハードウェアには不向き
- クラウドコンピューティングのコストが蓄積する可能性
2. 技術的な複雑さ
- コンシューマー向けアプリと比較して学習曲線が急
- パラメーターとプロンプトの理解が必要
- セルフホストのセットアップの複雑さ
- 最適化には技術的な専門知識が必要な場合がある
3. 処理速度
- 単純な編集のためのいくつかの専用ツールよりも遅い
- 画像解像度とともに推論時間が増加
- バッチ処理にはキュー管理が必要な場合がある
- リアルタイムのインタラクティブな編集には理想的ではない
4. 限定的な可用性
- 比較的新しいプラットフォーム(2025年8月)
- 確立されたツールと比較してエコシステムが小さい
- 初期のチュートリアルやコミュニティリソースが少ない
- 統合オプションはまだ開発中
5. プロンプトへの依存
- 品質はプロンプトエンジニアリングに大きく依存
- 望ましい結果を達成するために反復が必要な場合がある
- 効果的なプロンプトの学習曲線
- 指示が曖昧な場合、結果が一貫しない
6. 特化した焦点
- 生成よりも主に編集に最適化されている
- 一部のシナリオでは純粋な生成モデルに匹敵しない場合がある
- 卓越したテキストレンダリングはモデルサイズとのトレードオフを伴う
- トレーニングされたドメイン内で最良の結果が得られる
実用的なヒントとベストプラクティス
プロンプトエンジニアリング戦略
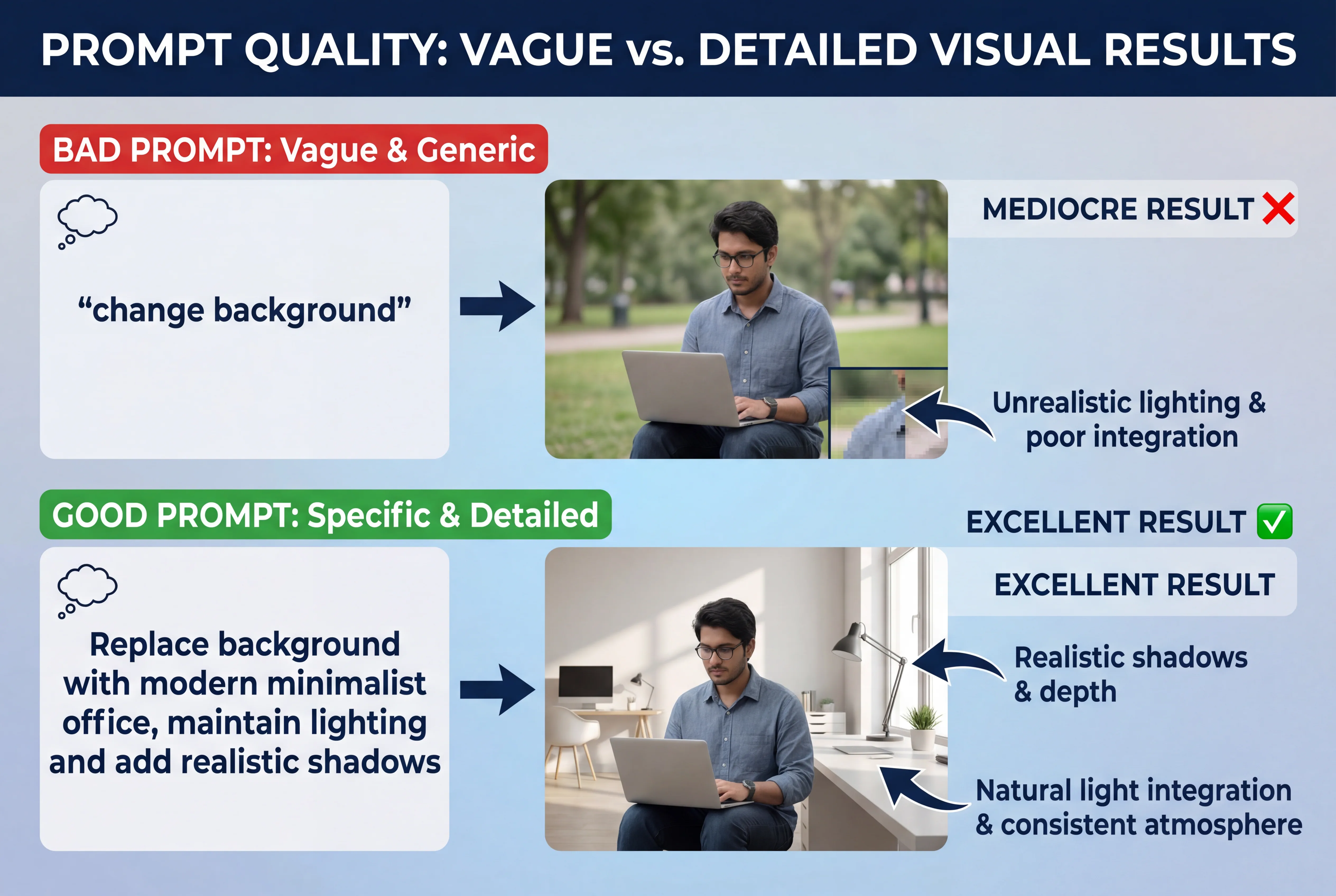
1. プロンプトを効果的に構成する
悪いプロンプト: 「Change the background」(背景を変えて) 良いプロンプト: 「Replace the current background with a modern minimalist office setting, maintaining the original lighting direction and adding realistic shadows under the subject」(現在の背景をモダンでミニマリストなオフィス設定に置き換え、元の照明方向を維持し、被写体の下にリアルな影を追加して)
主要なコンポーネント:
- アクション:何を変更するか(置換、追加、削除、修正)
- ターゲット:編集する特定の要素
- 詳細:望ましい特徴
- 制約:変更せずに残すべきもの
- スタイルノート:品質または美的要件
2. 増分編集を使用する
複雑な変換の場合、編集をステップに分割します:
- ステップ1:主要な構造変更
- ステップ2:色と照明の調整
- ステップ3:詳細の洗練
- ステップ4:テキストと仕上げ
3. ネガティブプロンプトを活用する
望ま ない ものを指定します:
- 「Remove the watermark without leaving artifacts」(アーティファクトを残さずに透かしを削除)
- 「Change the shirt color but keep the original wrinkles and folds」(シャツの色を変えるが、元のしわやひだは維持)
- 「Add text without obscuring the main subject」(主体を隠さずにテキストを追加)
パラメーターチューニングガイド
ガイダンススケール(Guidance Scale / CFG Scale):
- 3.0-5.0:より創造的、緩い解釈
- 5.0-7.5:バランス(推奨される開始点)
- 7.5-10.0:プロンプトへの厳密な順守
- 10.0+:非常に文字通り、品質が低下する可能性
推論ステップ(Inference Steps):
- 20-30ステップ:クイックプレビュー、ラフな編集
- 40-50ステップ:標準品質(推奨)
- 60-80ステップ:高品質、これを超えると収穫逓減
- Lightningモデル:4-8ステップに最適化
編集強度(Edit Strength):
- 0.3-0.5:微妙な修正、元のコンテンツの大部分を保持
- 0.5-0.7:バランスの取れた変更(デフォルト範囲)
- 0.7-0.9:実質的な変換
- 0.9-1.0:ほぼ完全な再構築
品質の最適化
1. 入力画像の準備
- 高解像度のソース画像を使用(1024x1024以上)
- オリジナルで良好な照明を確保
- クリーンで非圧縮のフォーマット(PNG推奨)
- 明確な被写体の定義
2. 反復的な洗練
- 複数のバリエーションを生成
- 結果を比較し、最良のアプローチを特定
- 初期結果に基づいてプロンプトを洗練
- 成功した編集を将来の作業の参考に使用
3. バッチ処理の効率
- 類似した編集をグループ化
- 再利用可能なワークフローテンプレートを作成
- 一貫したパラメーターセットを維持
- 成功した構成を文書化
4. テキスト編集のベストプラクティス
- 追加または置換する正確なテキストを指定
- 関連する場合はフォントスタイルの好みに言及
- テキストの位置を明確に示す
- 言語と文字セットの要件を考慮
避けるべき一般的な落とし穴
❌ 過度に複雑な単一プロンプト
複雑な編集は複数のステップに分解する
❌ 変更されていない領域の無視
一貫性を保つべきものを常に指定する
❌ 誤った解像度の期待
出力ニーズを入力品質に合わせる
❌ プロンプトテストの怠慢
最良の結果を得るためにプロンプトを反復し、洗練させる
❌ 一貫性のないパラメーター
成功したパラメーターの組み合わせを文書化して再利用する
ワークフローテンプレート
Eコマース商品編集:
1. 背景の削除/置換
2. 色補正と強調
3. サイズの標準化
4. 命名規則を使用したバッチエクスポートマーケティング資料のローカライズ:
1. テキストの識別と抽出
2. 翻訳の準備
3. フォントマッチングを使用したテキスト置換
4. 言語間での品質検証コンテンツ制作パイプライン:
1. ベース画像の選択
2. スタイルの適用または変更
3. テキストオーバーレイまたは変更
4. 異なるプラットフォーム向けのフォーマットエクスポートよくある質問 (FAQ)
Q1:Qwen Image Editは無料で使用できますか?
A:はい、Qwen Image EditはApache 2.0ライセンスの下でオープンソース化されています。セルフホストの場合、個人および商用目的で無料で使用できます。クラウドベースのサービスは、プロバイダーによっては従量課金の料金が発生する場合があります。
Q2:Qwen Image Editをローカルで実行するにはどのGPUが必要ですか?
A:最適なパフォーマンスを得るには、24GB VRAMを搭載したNVIDIA RTX 4090を推奨します。ただし、品質や速度は低下しますが、16GB VRAMを搭載したGPUで量子化バージョン(FP8またはGGUF)を実行することは可能です。ローカルハードウェアなしでの本番利用には、SeaDance AI のようなプラットフォームを検討してください。
Q3:Qwen Image Editはゼロから画像を生成できますか、それとも既存の画像を編集するだけですか?
A:Qwen Image Editは既存の画像の編集に最適化されていますが、テキストから画像を生成することもできるQwen-Image基盤モデル上に構築されています。ただし、純粋なテキストから画像への生成には、ベースのQwen-Imageモデルの方が適しています。
Q4:Qwen Image EditはPhotoshopと比べてどうですか?
A:Qwen Image Editは、Photoshopでは多大な手作業を必要とするAI駆動のセマンティック編集や自動変換に優れています。一方、Photoshopは、より精密な手動制御と幅広い専門ツールを提供します。これらは補完的な役割を果たします。QwenはAI支援による一括編集や複雑な変換に、Photoshopは微調整された手作業に使用します。
Q5:Qwen Image Editを商用プロジェクトに使用できますか?
A:はい、Apache 2.0ライセンスは商用利用を許可しています。セルフホストの場合、追加の制限はありません。クラウドプラットフォームを使用する場合は、常にライセンス条項とサービス固有の条項を確認してください。
Q6:Qwen Image Editはテキスト編集でどの言語をサポートしていますか?
A:Qwen Image Editは、中国語と英語のテキストレンダリングと編集において優れたサポートを提供します。他の言語も範囲はある程度処理できますが、バイリンガルな中英機能がその最大の強みです。
Q7:画像の編集にはどのくらい時間がかかりますか?
A:処理時間はハードウェアと設定によって異なります。標準設定(50ステップ)のRTX 4090では、1024x1024画像あたり3〜5秒と予想されます。Lightningモデルでは、これを2秒未満に短縮できます。解像度が高く、ステップ数が多いほど、処理時間は比例して増加します。
Q8:一度に複数の画像を編集できますか?
A:はい、Qwen Image Editはバッチ処理をサポートしています。Qwen-Image-Edit-2509バージョンでは、マルチ画像入力(2〜3枚の画像を1回の編集に組み合わせる)もサポートしています。複数の個別の編集をバッチ処理できるかどうかは、実装とハードウェアの能力に依存します。
Q9:どのファイル形式がサポートされていますか?
A:Qwen Image Editは、JPEG、PNG、WebPなどの標準的な画像形式で動作します。特に透明度が関与する場合は、最高品質を得るためにPNGを推奨します。
Q10:編集の品質を向上させるにはどうすればよいですか?
A:3つの分野に焦点を当ててください:
- より良いプロンプト:必要な変更について具体的で詳細かつ明確にする
- 最適なパラメーター:推奨設定から始めて、結果に基づいて調整する
- 高品質な入力:高解像度で照明の良いソース画像を使用する
Q11:画像解像度に制限はありますか?
A:厳格な制限はありませんが、VRAMに基づく実用的な制約が存在します。ほとんどのコンシューマー向けGPUは、最大1024x1024まで問題なく処理できます。より高い解像度には、より多くのVRAMまたはタイリング技術が必要です。クラウドサービスは解像度制限を課す場合があります。
Q12:Qwen Image Editは画像のメタデータを保持できますか?
A:これは実装に依存します。コアモデルは本質的にメタデータを保持しませんが、編集プロセス中にEXIFデータやその他のメタデータを維持するラッパースクリプトを実装できます。
Q13:Qwen Image Editはどのくらいの頻度で更新されますか?
A:Qwen-Image-Edit-2509リリースが示すように、アリババは毎月の反復スケジュールに従っています。更新の発表や新機能については、公式チャンネルを確認してください。
Q14:特定のユースケースに合わせてQwen Image Editを微調整できますか?
A:はい、オープンソースモデルとして、独自のデータセットでQwen Image Editを微調整できます。これには機械学習の技術的専門知識と多大な計算リソースが必要ですが、専門的なアプリケーションのパフォーマンスを劇的に向上させることができます。
Q15:サポートを受けたり問題を報告したりするにはどこに行けばよいですか?
A:サポートは以下を通じて利用可能です:
- 公式Qwen-ImageリポジトリのGitHub issue
- コミュニティフォーラムとDiscordチャンネル
- Qwenチームによるドキュメントとチュートリアル
- サードパーティプラットフォームが専用のサポートチャンネルを提供する場合があります
結論:AI画像編集の未来
Qwen Image Editは、AI駆動の画像操作技術の進化における重要なマイルストーンを表しています。最先端のセマンティック理解とピクセルパーフェクトな外観制御を組み合わせることで、アリババのQwenチームは、自動AI生成とプロの手動編集の間のギャップを埋めるツールを作成しました。
重要なポイント
個人とクリエイター向け:
- Qwen Image Editは、プログレードの画像編集機能を民主化します
- オープンソースのアクセシビリティにより、高度なAIツールのコスト障壁が取り除かれます
- 卓越したテキストレンダリング機能により、多言語コンテンツ制作における長年の課題が解決されます
企業と法人向け:
- コンテンツ制作とローカライズにおける大幅なコスト削減
- 大容量の画像編集ニーズに対応するスケーラブルなソリューション
- クラウドサービスからオンプレスインストールまで、柔軟な展開オプション
開発者と研究者向け:
- オープンアーキテクチャにより、カスタマイズと拡張が可能になります
- 専門的なアプリケーションを構築するための強固な基盤
- 活発な開発により、継続的な改善が保証されます
今後の展望
初期のQwen-Image-Editから2509バージョンへの急速な進化は、この技術を推進するというアリババのコミットメントを示しています。毎月の反復により、マルチ画像編集や一貫性の向上などの大幅な改善がもたらされており、将来の軌跡は明らかです。AI画像編集は、より強力でアクセスしやすくなり、クリエイティブなワークフローに不可欠なものになり続けるでしょう。
Qwen Image Editのようなモデルが成熟するにつれて、以下が期待されます:
- さらに洗練されたセマンティック理解
- リアルタイムのインタラクティブな編集機能
- デザインおよび制作ツールとのより広範な統合
- 編集セッション全体での一貫性の強化
- より少ない計算リソースで済むより効率的なモデル
今日から始めましょう
ワークフローを合理化したいグラフィックデザイナーであれ、商品写真を拡大する必要があるEコマース企業であれ、次世代のクリエイティブツールを構築する開発者であれ、Qwen Image Editは探索する価値のある魅力的な機能を提供します。
深く掘り下げる準備ができている人は、Seedance AI のようなアクセス可能なプラットフォームから始めて、技術を直接体験してください。その後、ニーズが高まるにつれて、より深い統合オプションを検討してください。強力な機能、オープンソースの柔軟性、および活発な開発の組み合わせにより、Qwen Image Editは2025年以降も注目し、使用する価値のある技術となっています。
AI駆動の画像編集の革命はここにあり、Qwen Image Editがその先頭に立っています。問題は、これらの技術を採用するかどうかではなく、ますますAI主導のビジュアルランドスケープで競争力を維持するために、いかに早くそれらをクリエイティブプロセスに統合できるかです。
画像編集ワークフローを変革する準備はできましたか? 今すぐQwen Image Editを探索し、AIがどのようにしてクリエイティブな能力を前例のないレベルに引き上げることができるかを発見してください。